本文代码基于 Kubernetes v1.26 展开。
kube-proxy,以下简称 kp,是负责实现 Service VIP 机制(ExternalName类型除外)的组件。
代理模式
kp 的代理模式可由配置文件来指定:kp 的配置通过 ConfigMap 实现,ConfigMap 的配置参数合法性并不会被 kp 全部验证,比如宿主机是否禁止使用了 iptables 命令。
kubectl describe -n kube-system configmaps kube-proxy
iptables
该模式下,kp 监听 k8s 控制面增加和移除 Service、EndpointSlice 对象的事件。
- kp 只能看到通过 readiness 探针测试的后端 pod,从而避免将流量发送到失败的 pod 上
对于一个大型集群来说,kp 对于 iptables 规则的更新成为了 Service 性能的瓶颈,对此 kp 存在两个性能优化参数:
iptables:
minSyncPeriod: 1s # kp 与内核同步 iptables 的时机,默认在 svc 等资源更新后 1s 再同步
syncPeriod: 30s # kp 与内核同步 iptables 的周期,默认 30s 同步一次,无论是否有资源更新
可见minSyncPeriod的值越大,在此期间内的所有更新事件就会聚合,从而进行统一的更新,类似于 Istio 控制面 Pilot 的 debounce 机制;但缺点是会造成规则更新不及时。
ipvs
kp 启动时会先检测内核 ipvs 模块是否可用,不可用时则回退至 iptables 模式。属于贴心的验证。
该模式下,kp 是通过调用netlink的接口来创建 ipvs 规则的。得益于 ipvs 底层使用的哈希表结构存储规则,在流量转发时拥有更低的延迟、规则同步时拥有更快的性能。
Proxy Server
kp 作为 Daemonset 资源,其 pod 运行在每个 Node 上,而它本质上就是一个二进制服务。
该服务的命令行入口点在cmd/kube-proxy/proxy.go中定义,其命令的执行方式也较为直观:
func NewProxyCommand() *cobra.Command {
// 初始化 kp 的配置,各项都还是默认值
opts := NewOptions()
cmd := &cobra.Command{
Use: "kube-proxy",
RunE: func(cmd *cobra.Command, args []string) error {
// 将必填配置字段值填充到 kp 配置中
opts.Complete()
// 验证 kp 配置参数的合法性
opts.Validate()
// 初始化 kp 服务器并运行
opts.Run()
|
opts.proxyServer = NewProxyServer(opts)
opts.runLoop()
return nil
},
}
// ...
return cmd
}
初始化
opts.Run首先初始化了 kp 服务,该服务的结构体如下所示:
type ProxyServer struct {
Config *kubeproxyconfig.KubeProxyConfiguration // kp 配置
Client clientset.Interface // 与 api-server 交互的客户端,这部分配置由 ConfigMap 的 clientConnection 字段描述
Broadcaster events.EventBroadcaster
Recorder events.EventRecorder // 通过 Broadcaster 创建,用于上报来源是 kube-proxy 的事件
Conntracker Conntracker // 连接追踪相关,为 nil 则忽略处理
NodeRef *v1.ObjectReference // kp 所在 node 的引用
HealthzServer healthcheck.ProxierHealthUpdater // 健康检查,运行在 10256 端口,过期时间为 2 倍的 iptables.sync_period 时间,即 1min
Proxier proxy.Provider // 对应 iptables 或 ipvs 真实的代理服务
}
初始化涉及的内容较多,但最重要的可以总结以下几点。
Hostname
首先获取 Node 的 Hostname,默认使用os.Hostname获取;但如果在 kp 配置中存在HostnameOverride,则使用该配置。实际上,这一配置项在 kp 启动时就被传入了,如下所示:
Containers:
kube-proxy:
Image: registry.k8s.io/kube-proxy:v1.26.0
Port: <none>
Host Port: <none>
Command:
/usr/local/bin/kube-proxy
--config=/var/lib/kube-proxy/config.conf # 挂载的 ConfigMap
--hostname-override=$(NODE_NAME)
State: Running
通过 Hostname 就可以完成 Proxy Server 对应NodeRef的初始化。
Node IP
Hostname 的另外一个关键用途就是用于获取 Node 的 IP,该 IP 的获取存在以下规则:
func detectNodeIP(client clientset.Interface, hostname, bindAddress string) net.IP {
// 规则1: 优先使用 kp `bindAddress` 指定的 ip,表示 kp server 用于提供服务的地址
nodeIP := netutils.ParseIPSloppy(bindAddress)
// 规则2: 若是 0.0.0.0 或 :: 这样未指定的 ip,则通过 hostname 获取;获取到的 ip 即 node 的第一个 internal-ip,详见 pkg/util/node/node.go #L72
if nodeIP.IsUnspecified() {
nodeIP = utilnode.GetNodeIP(client, hostname)
}
// 规则3: 默认情况下,即指定使用 ipv4 的回环地址
if nodeIP == nil {
nodeIP = netutils.ParseIPSloppy("127.0.0.1")
}
return nodeIP
}
Proxier
根据 kp 的mode配置可以选择不同的代理模式,再根据上述获取的 Node IP 可以选择不同的网络协议栈,比如 ipv4 或 ipv6 甚至是 dual stack。不同的代理模式和网络协议栈会提供不同的 Proxy Provider,简称 Proxier:
- iptables/ipvs 模式下的 dual stack,使用
DualStackProxier并初始化 - iptables/ipvs 模式下的 single stack,则使用普通的
Proxier并初始化
Proxier 的代码作为 kp 的核心功能,存在于pkg/proxy目录下,包括 iptables 和 ipvs 两个子部分。
运行方式
kp 服务的运行是一个循环监听的结构,即对于 Node 本地的 config 配置文件进行循环监听并应用其更新到 kp 服务。Proxy Server 的运行逻辑:
- 首先配置并启动 OOM Adjuster、事件分发、健康检查、遥测服务
- 涉及一个 OOM 分数的概念:OOM 是指进程尝试使用超过其分配的内存时,内核会终止该进程以释放内存;而 OOM 分数则是用于确定在系统出现内存不足的情况下,哪个进程应被终止。该分数值域为
[-1000,+1000],分越高表示进程更容易被选中以释放内存;分越低则相反。一般在 Pod 中设置 resources 字段的limits和requests来控制容器内存限制和请求,k8s 将自动根据容器的配置来计算 OOM 分数 - QoS 类型也可通过 OOM 分数来反应,比如 -998 分对应 Guaranteed、1000 分对应 BestEffort 等
- 涉及一个 OOM 分数的概念:OOM 是指进程尝试使用超过其分配的内存时,内核会终止该进程以释放内存;而 OOM 分数则是用于确定在系统出现内存不足的情况下,哪个进程应被终止。该分数值域为
- 配置连接追踪模块参数
- 创建并运行的两个 Informer Factory:分别处理 Service 和 EndpointSlice 资源、Node 资源
- 最后启动 Proxier 同步循环
func (s *ProxyServer) Run() error {
// kp 服务通过直接指定 `oomScoreAdj`来设置 OOM 分数,该分数默认值为 -999,表示最不可能被释放内存的进程。
var oomAdjuster *oom.OOMAdjuster
if s.Config.OOMScoreAdj != nil {
oomAdjuster = oom.NewOOMAdjuster()
oomAdjuster.ApplyOOMScoreAdj(0, int(*s.Config.OOMScoreAdj))
}
// 开启事件的分发
if s.Broadcaster != nil {
stopCh := make(chan struct{})
s.Broadcaster.StartRecordingToSink(stopCh)
}
// 开启健康检查服务与遥测服务
var errCh chan error
if s.Config.BindAddressHardFail {
errCh = make(chan error)
}
serveHealthz(s.HealthzServer, errCh)
serveMetrics(s.Config.MetricsBindAddress, s.Config.Mode, s.Config.EnableProfiling, errCh)
// 若有需要,则调节 conntrack 即连接追踪模块;该模块对于 windows 系统无效
if s.Conntracker != nil {
// 详情见下文
}
// 创建 Informer Factory 并指定 List 操作的标签选择器,即 kp **不会获取** 到:
//- 指定 servic proxy 的 Service 资源,即 Service 不再使用 kp 作为 proxy,这类资源携带标签 'service.kubernetes.io/service-proxy-name'
//- 没有指定 Cluster IP 的 Service 资源,即 Headless Service,这类资源携带标签 'service.kubernetes.io/headless'
noProxyName, err := labels.NewRequirement(apis.LabelServiceProxyName, selection.DoesNotExist, nil)
noHeadlessEndpoints, err := labels.NewRequirement(v1.IsHeadlessService, selection.DoesNotExist, nil)
labelSelector := labels.NewSelector()
labelSelector = labelSelector.Add(*noProxyName, *noHeadlessEndpoints)
informerFactory := informers.NewSharedInformerFactoryWithOptions(s.Client, s.Config.ConfigSyncPeriod.Duration,
informers.WithTweakListOptions(func(options *metav1.ListOptions) {
options.LabelSelector = labelSelector.String()
}))
// 创建 Services 和 EndpointSlice 资源的 Informer,然后开始运行,进行资源同步
serviceConfig := config.NewServiceConfig(informerFactory.Core().V1().Services(), s.Config.ConfigSyncPeriod.Duration)
serviceConfig.RegisterEventHandler(s.Proxier)
go serviceConfig.Run(wait.NeverStop)
endpointSliceConfig := config.NewEndpointSliceConfig(informerFactory.Discovery().V1().EndpointSlices(), s.Config.ConfigSyncPeriod.Duration)
endpointSliceConfig.RegisterEventHandler(s.Proxier)
go endpointSliceConfig.Run(wait.NeverStop)
// 开启 Informer Factory
informerFactory.Start(wait.NeverStop)
// 再创建一个 Informer Factory 可根据 Hostname 选择 Node 资源
currentNodeInformerFactory := informers.NewSharedInformerFactoryWithOptions(s.Client, s.Config.ConfigSyncPeriod.Duration,
informers.WithTweakListOptions(func(options *metav1.ListOptions) {
options.FieldSelector = fields.OneTermEqualSelector("metadata.name", s.NodeRef.Name).String()
}))
// 创建 Node 资源的 Informer,然后开启运行
nodeConfig := config.NewNodeConfig(currentNodeInformerFactory.Core().V1().Nodes(), s.Config.ConfigSyncPeriod.Duration)
nodeConfig.RegisterEventHandler(s.Proxier)
go nodeConfig.Run(wait.NeverStop)
currentNodeInformerFactory.Start(wait.NeverStop)
// 方法名很具象,就像出生婴儿呱呱坠地一般,表示 kp 服务已经成功启动
s.birthCry()
\
s.Recorder.Eventf(s.NodeRef, nil, api.EventTypeNormal, "Starting", "StartKubeProxy", "")
// 开启各代理模式 Proxier 的同步循环
go s.Proxier.SyncLoop()
return <-errCh
}
Conntracker
若 kp 启用了连接追踪,则会在启动 kp 服务前先进行一些参数的调节,这些参数都是 Linux Kernel Netfilter 子系统 conntrack 模块对外暴露的参数,可直接使用 sysctl 予以调节(实际上 kp 也是这么做的);在 kp 中可调节的参数只包括 3 种:
type Conntracker interface {
// SetMax adjusts `nf_conntrack_max`.
SetMax(max int) error
// SetTCPEstablishedTimeout adjusts `nf_conntrack_tcp_timeout_established`.
SetTCPEstablishedTimeout(seconds int) error
// SetTCPCloseWaitTimeout `nf_conntrack_tcp_timeout_close_wait`.
SetTCPCloseWaitTimeout(seconds int) error
}
即只规定了最大连接数,与 TCP 连接建立、连接关闭的超时时间。
if s.Conntracker != nil {
max, err := getConntrackMax(s.Config.Conntrack)
if max > 0 {
err := s.Conntracker.SetMax(max)
}
if s.Config.Conntrack.TCPEstablishedTimeout != nil && s.Config.Conntrack.TCPEstablishedTimeout.Duration > 0 {
timeout := int(s.Config.Conntrack.TCPEstablishedTimeout.Duration / time.Second)
s.Conntracker.SetTCPEstablishedTimeout(timeout)
}
if s.Config.Conntrack.TCPCloseWaitTimeout != nil && s.Config.Conntrack.TCPCloseWaitTimeout.Duration > 0 {
timeout := int(s.Config.Conntrack.TCPCloseWaitTimeout.Duration / time.Second)
s.Conntracker.SetTCPCloseWaitTimeout(timeout)
}
}
Service Informer
Service、EndpointSlice 作为 kp 创建的第一个 Informer 监听的资源,它们在注册 Informer 时,就指定了针对各自资源操作所定义的 handler 回调。以 Service 资源为例,其初始化 Informer 的内容如下:
type ServiceConfig struct {
listerSynced cache.InformerSynced
eventHandlers []ServiceHandler
}
func NewServiceConfig(serviceInformer coreinformers.ServiceInformer, resyncPeriod time.Duration) *ServiceConfig {
result := &ServiceConfig{
listerSynced: serviceInformer.Informer().HasSynced,
}
serviceInformer.Informer().AddEventHandlerWithResyncPeriod(
cache.ResourceEventHandlerFuncs{
AddFunc: result.handleAddService, // 增
UpdateFunc: result.handleUpdateService, // 改
DeleteFunc: result.handleDeleteService, // 删
},
resyncPeriod,
)
return result
}
这些handleXXXService回调虽然是ServiceConfig结构体的方法,但它们本质上,都在遍历ServicConfig.eventHandlers并对其中的每个事件 handler 调用该操作对应的方法。这些eventHandlers[i].OnServiceXXX也正是由 Proxier 提供的:
for i := range c.eventHandlers {
c.eventHandlers[i].OnServiceXXX()
}
ServicConfig.eventHandlers是通过ServiceConfig.RegisterEventHandler方法提交的,而且要在 Informer 运行前把 handler 都提前注册好。
func (c *ServiceConfig) RegisterEventHandler(handler ServiceHandler) {
c.eventHandlers = append(c.eventHandlers, handler)
}
func (c *ServiceConfig) Run(stopCh <-chan struct{}) {
// 等待 service 相关资源从 apiserver 同步到本地缓存
if !cache.WaitForNamedCacheSync("service config", stopCh, c.listerSynced) {
return
}
for i := range c.eventHandlers {
c.eventHandlers[i].OnServiceSynced() // 见下文 proxier 内容
}
}
同样 EndpointSlice 资源对应的 Informer 创建过程和工作模式也同上所述,这里不再展开赘述。
Node Informer
Node 作为 kp 创建的第二个 Informer 类型,其初始化内容和工作模式与上述一致。唯一不同的地方就是在 handler 回调的传入:
nodeInformer.Informer().AddEventHandlerWithResyncPeriod(
cache.ResourceEventHandlerFuncs{
AddFunc: result.handleAddNode,
UpdateFunc: result.handleUpdateNode,
DeleteFunc: result.handleDeleteNode,
},
resyncPeriod,
)
这三个handleXXXNode方法同样执行的也是 Proxier 对应的OnNodeXXX方法,具体工作见下文 Proxier 内容。
Proxy Provider
在ProxyServer.Run方法的最后,通过调用Proxier.SyncLoop开启了 kp 的正式工作。
iptables proxier
此部分代码在
pkg/proxy/iptables/proxier.go路径下。此处以 single ipv4 stack 的 proxier 为例。
经过上述的分析,可以自然推测出,proxier 至少需要 9 个对资源操作的 handler 方法,即:
for resource in ["Service", "EndponintSlice", "Node"]:
for cmd in ["Add", "Update", "Delete"]:
=> On${resource}${cmd}()
其实,除了上述 handler 之外,每种资源还有 3 个名为OnXXXSynced的 handler,它们在各种资源对象同步到本地缓存之后被调用。以OnServiceSynced为例,其于ServiceConfig.Run方法中,在WaitForNamedCacheSync之后被调用,而且总共也仅被调用这一次。
所以这些 handler 的目的就是:用于标记 Proxier 对应资源的缓存初始化完成,并后续尝试强制 iptables 规则同步。
func (proxier *Proxier) OnServiceSynced() {
proxier.mu.Lock()
proxier.servicesSynced = true
proxier.setInitialized(proxier.endpointSlicesSynced)
proxier.mu.Unlock()
// Sync unconditionally - this is called once per lifetime.
proxier.forceSyncProxyRules()
\
\
// 强制进行同步,不一定同步成功
proxier.needFullSync = true // 全量同步
proxier.syncProxyRules()
}
P.S. OnNodeSynced是个意外,这个方法为空,所以什么都不会发生。故后文会忽略。
Resources Handler
对于 Service、EndpointSlice 来说,它们对资源操作的 handler 都有着以下形式:
- 对于增、删操作而言,它们本质都是更新操作
- 每次操作完成后,都会使用
proxier.Sync方法立马与 iptables 进行同步
func (proxier *Proxier) OnServiceAdd(service *v1.Service) {
proxier.OnServiceUpdate(nil, service)
}
func (proxier *Proxier) OnServiceDelete(service *v1.Service) {
proxier.OnServiceUpdate(service, nil)
}
func (proxier *Proxier) OnServiceUpdate(oldService, service *v1.Service) {
// 将 old 与 new Service 的 spec 进行对比,若存在变化则返回 true
// 并且,只有经历过初始化阶段的 proxier,才可以进行同步
if proxier.serviceChanges.Update(oldService, service) && proxier.isInitialized() {
proxier.Sync() // sync ASAP
}
}
func (proxier *Proxier) Sync() {
if proxier.healthzServer != nil {
proxier.healthzServer.QueuedUpdate()
}
metrics.SyncProxyRulesLastQueuedTimestamp.SetToCurrentTime()
proxier.syncRunner.Run()
\
\
// syncRunner.Run 方法执行的仍然是 syncProxyRules 方法
async.NewBoundedFrequencyRunner("sync-runner", proxier.syncProxyRules, minSyncPeriod, time.Hour, burstSyncs)
}
syncProxyRules
该方法是所有 iptables 规则被生成(iptables-save)、保存(iptables-restore)的地方,也是整个 iptables proxier 的核心方法,整个方法长达 800 行。此处不全部贴出,其具体实现可参考 iptables/proxier.go。
iptables-save将当前 iptables 规则保存到文件中,iptables-restore将这些规则重新加载到内核中
同步时机
iptables 的同步时机即该方法的调用时机,其存在三个调用时机(前文已经提了两个了,这里再做下扩充):
- 在
OnServiceSynced和OnEndpointSlicesSynced中被调用,用于进行 iptables 规则的强制同步- 上文在代码注释中提到该强制同步不一定成功,具体是指:两个方法中只有一个方法的强制同步会成功。因为通过观察这两个方法的实现就可以发现,在两种资源各自设置初始化状态时,使用的是另外一个资源的同步状态,这就要求两种资源必须全部处于已同步的状态时,iptables 规则的同步才会起效
func (proxier *Proxier) OnServiceSynced() { proxier.mu.Lock() proxier.servicesSynced = true proxier.setInitialized(proxier.endpointSlicesSynced) proxier.mu.Unlock() proxier.forceSyncProxyRules() } func (proxier *Proxier) OnEndpointSlicesSynced() { proxier.mu.Lock() proxier.endpointSlicesSynced = true proxier.setInitialized(proxier.servicesSynced) proxier.mu.Unlock() proxier.forceSyncProxyRules() }- 通过观察 kp 的日志(logs -v 10)可以明确这一点:
I0515 08:11:07.237135 1 shared_informer.go:262] Caches are synced for endpoint slice config # 只有 EndpointSlice 一个资源缓存就绪了是不会开始规则同步的 I0515 08:11:07.237148 1 config.go:233] "Calling handler.OnEndpointSlicesSynced()" I0515 08:11:07.237305 1 proxier.go:812] "Not syncing iptables until Services and Endpoints have been received from master" I0515 08:11:07.237323 1 proxier.go:812] "Not syncing iptables until Services and Endpoints have been received from master" I0515 08:11:07.237088 1 shared_informer.go:285] caches populated I0515 08:11:07.237356 1 shared_informer.go:262] Caches are synced for service config # 等 service 缓存就绪后,才成功同步 iptables 规则 I0515 08:11:07.237452 1 config.go:324] "Calling handler.OnServiceSynced()" I0515 08:11:07.237710 1 service.go:437] "Adding new service port" portName="default/kubernetes:https" servicePort="10.96.0.1:443/TCP - 在 Monitor 中被调用,Monitor 用于周期性地检测指定的 iptables 表是否被外部工具 flush 掉了(比如防火墙发生 reload);若检测到被 flush 掉了,则进行 iptables 规则的强制同步
- 该 Monitor 监视 mangle、nat、packet-filter 这三张 iptables 表
- 该 Monitor 通过创建 canary chain(金丝雀链)来检测 iptables 规则的变化,即创建一个用于检测规则变化的虚拟链。这个虚拟链包含了一些特殊的规则,这些规则会在防火墙规则被修改时触发报警
- 在 Service、EndpointSlice、Node 这三种资源分别发生 Add、Update、Delete 事件时,通过
proxier.syncRunner.Run主动进行一次 iptables 规则的同步- 同时
proxier.syncRunner也会间歇性地自动执行Run方法,来同步 iptables 规则
- 同时
同步方式
iptables 规则的同步方式分为两种:全量(full)和部分(partial)。其中:
- 所有的强制同步方法均为全量同步方式,即
forceSyncProxyRules方法 - 所有自然使用
syncProxyRules方法的,均为先尝试部分同步(等失败后)再使用全量方式
关于部分同步的方式,由 #110268 提出,并于 v1.26 引入,是一种增强 iptables 同步性能的同步方式。具体来说,iptables-restore存在一个限制:若要更新一个 iptables chain 中的任意一个 iptables rule,则需要更新这个 iptables chain 的所有 rules;当然若没有 iptables rule 的更新,其所在的 iptables chain 也不会发生更新。在部分同步方式引入之前,kp 一直采用全量的同步方式,即每次同步都会针对所有 iptables rules 进行同步,这就会导致所有 iptables chains 的所有 iptables rules 全部进行更新。当集群规模很大时,这种同步方式便成为了一个性能瓶颈。
然而在实际生产中,kp 其实每次同步发生的变化都不大,但对于一个大集群来说,每更新 1 个 Service 的 iptables rule 就要引发全量地再同步其他 10000 个不变的 iptables rule,这多少有些不值得。所以引入了部分的同步方式。部分同步方式的工作原理也较为简单,就是追踪自上次iptables-restore之后,Service 和 EndpointSlice 资源是否发生了变化。若发生了变化,则只针对变化的部分生成 iptables rule,并只更新该 rule 所在的 iptables chain。
func (proxier *Proxier) syncProxyRules() {
// ...
// v1.26 时部分同步作为 kp 的一个 feature,可通过配置启动;v1.27 时默认开启
tryPartialSync := !proxier.needFullSync && utilfeature.DefaultFeatureGate.Enabled(features.MinimizeIPTablesRestore)
var serviceChanged, endpointsChanged sets.String
if tryPartialSync { // 获取自上次同步后,Service、EndpointSlice 资源所产生的新的变化
serviceChanged = proxier.serviceChanges.PendingChanges()
endpointsChanged = proxier.endpointsChanges.PendingChanges()
}
// ...
success := false
defer func() {
if !success {
proxier.syncRunner.RetryAfter(proxier.syncPeriod)
// 部分同步失败后会等待重试,只不过重试使用全量同步
proxier.needFullSync = true
}
}()
// ...
for svcName, svc := range proxier.svcPortMap {
// ...
// 对于没有任何变化的 Service、EndpointSlice 资源则直接跳过同步
if tryPartialSync && !serviceChanged.Has(svcName.NamespacedName.String()) && !endpointsChanged.Has(svcName.NamespacedName.String()) {
continue
}
// ...
}
// ...
}
更多有关部分同步的技术细节、性能提升表现可查看 KEP-3453。
规则分析
如何构建规则非本文重点。本节将通过查看为不同服务类型创建的 iptables 规则来一览 iptables proxier 的工作内容。这里并不对ExternalName类型的 Service 展开,因为正如本文开头所说,它不属于 kp 的工作范畴。
本节描述的所有 iptables 规则均可从 pkg/proxy/iptables/proxier_test.go 中复现。若无特别说明,Service 的ExternalTrafficPolicy默认采用cluster模式。
NodePort
集群内的所有节点都会配置自身去监听这个 NodePort 端口,在集群外可通过请求集群内任意一个节点的 NodePort 来访问 Service 服务。Service 在创建时,若 NodePort 非显式指定,则 kp 会为其自动分配一个未被占用的 NodePort。
假设 Service 的 ClusterIP 为 172.30.0.41,port 为 80,使用 TCP 协议,且 NodePort 显式指定为 3001;Service 代理了两个 Endpoint,其地址分别为 10.180.0.1:80、10.180.0.2:80,均使用 TCP 协议。生成的 iptables 规则如下所示:
*filter
:KUBE-SERVICES - [0:0]
:KUBE-EXTERNAL-SERVICES - [0:0]
:KUBE-FORWARD - [0:0]
:KUBE-NODEPORTS - [0:0]
:KUBE-PROXY-FIREWALL - [0:0]
# 配置在 FORWARD 链中接受转发带有 0x4000 标记的包,并将连接追踪状态为“无效”的包丢弃、状态为“已建立”的包接受
-A KUBE-FORWARD -m conntrack --ctstate INVALID -j DROP
-A KUBE-FORWARD -m comment --comment "kubernetes forwarding rules" -m mark --mark 0x4000/0x4000 -j ACCEPT
-A KUBE-FORWARD -m comment --comment "kubernetes forwarding conntrack rule" -m conntrack --ctstate RELATED,ESTABLISHED -j ACCEPT
COMMIT
*nat
:KUBE-SERVICES - [0:0]
:KUBE-NODEPORTS - [0:0]
:KUBE-POSTROUTING - [0:0]
:KUBE-MARK-MASQ - [0:0]
:KUBE-EXT-XPGD46QRK7WJZT7O - [0:0]
:KUBE-SVC-XPGD46QRK7WJZT7O - [0:0]
:KUBE-SEP-SXIVWICOYRO3J4NJ - [0:0]
:KUBE-SEP-LXVODXWDISEETFEF - [0:0]
-A KUBE-POSTROUTING -m mark ! --mark 0x4000/0x4000 -j RETURN #1
-A KUBE-POSTROUTING -j MARK --xor-mark 0x4000 #2
-A KUBE-POSTROUTING -m comment --comment "kubernetes service traffic requiring SNAT" -j MASQUERADE #3
-A KUBE-MARK-MASQ -j MARK --or-mark 0x4000 #4
-A KUBE-SERVICES -m comment --comment "ns1/svc1:p80 cluster IP" -m tcp -p tcp -d 172.30.0.41 --dport 80 -j KUBE-SVC-XPGD46QRK7WJZT7O #5
-A KUBE-NODEPORTS -m comment --comment ns1/svc1:p80 -m tcp -p tcp --dport 3001 -j KUBE-EXT-XPGD46QRK7WJZT7O #6
-A KUBE-SVC-XPGD46QRK7WJZT7O -m comment --comment "ns1/svc1:p80 cluster IP" -m tcp -p tcp -d 172.30.0.41 --dport 80 ! -s 10.0.0.0/8 -j KUBE-MARK-MASQ #7
-A KUBE-EXT-XPGD46QRK7WJZT7O -m comment --comment "masquerade traffic for ns1/svc1:p80 external destinations" -j KUBE-MARK-MASQ #8
-A KUBE-EXT-XPGD46QRK7WJZT7O -j KUBE-SVC-XPGD46QRK7WJZT7O #9
-A KUBE-SVC-XPGD46QRK7WJZT7O -m comment --comment "ns1/svc1:p80 -> 10.180.0.1:80" -m statistic --mode random --probability 0.5000000000 -j KUBE-SEP-SXIVWICOYRO3J4NJ #10
-A KUBE-SVC-XPGD46QRK7WJZT7O -m comment --comment "ns1/svc1:p80 -> 10.180.0.2:80" -j KUBE-SEP-LXVODXWDISEETFEF #11
-A KUBE-SEP-SXIVWICOYRO3J4NJ -m comment --comment ns1/svc1:p80 -s 10.180.0.1 -j KUBE-MARK-MASQ #12
-A KUBE-SEP-SXIVWICOYRO3J4NJ -m comment --comment ns1/svc1:p80 -m tcp -p tcp -j DNAT --to-destination 10.180.0.1:80 #13
-A KUBE-SEP-LXVODXWDISEETFEF -m comment --comment ns1/svc1:p80 -s 10.180.0.2 -j KUBE-MARK-MASQ #14
-A KUBE-SEP-LXVODXWDISEETFEF -m comment --comment ns1/svc1:p80 -m tcp -p tcp -j DNAT --to-destination 10.180.0.2:80 #15
-A KUBE-SERVICES -m comment --comment "kubernetes service nodeports; NOTE: this must be the last rule in this chain" -m addrtype --dst-type LOCAL -j KUBE-NODEPORTS #16
COMMIT
对经由 PREROUTING(非本节点访问)或 OUTPUT(本节点访问) 链的请求包,都会先进入 KUBE-SERVICES 链 #5,该链路规则与 ClusterIP 模式一致:
- 抵达 #7,将目的地址、端口为 Service IP、Port 但源地址非 Endpoint 网段的 TCP 请求通过 #4 置 0x4000 标记,表示之后需要进行源 IP 地址伪装,伪装为节点的 IP 地址,以便服务正常响应流量(后续做标记的目的都如此)
- 通过 #10 或 #11 时分别有一半的几率抵达 #12、#13 或 #14、#15,即基于随机策略的负载均衡
- 对于抵达 #12 的请求,若其源地址为 Endpoint 1 IP,则通过 #4 置 0x4000 标记;然后经由 #13 做 DNAT,将目的地址和端口映射为 Endpoint 1 对应的地址和端口,以访问服务的提供者
- 对于抵达 #14 的请求,所做处理也同上条所述
其次,会经过 KUBE-SERVICES 链 #16,将目的地址为本地 Node IP 的请求跳转到执行 NodePort 规则的设备。注意这个规则必须是 KUBE-SERVICES 链的最后一条规则,因为若它不是该链中的最后一个规则,那么它可能会被之后的规则所覆盖,从而导致流量无法被正确路由。
- 抵达 #6,对于目的端口为 3001 的 TCP 请求
- 抵达 #8,通过 #4 置 0x4000 标记
- 经由 #9 抵达 #7,后续步骤同上文描述的一致
最后在 POSTROUTING 链中,对请求进行源地址伪装(通过 SNAT)#3,这里进行源地址伪装的必要性:
client
\ ^
\ \
v \
node 1 <--SNAT-- node 2
| ^ -------->
| |
v |
endpoint
若 Endpoint 1、2 分别在 Node 1、2 上,客户端通过请求 Node2 的 NodePort 访问服务,Node 2 上的 iptables 负载均衡策略有几率将请求 DNAT 到 Endpoint 1;之后转发该请求后。若不进行 SNAT,则 Endpoint 1 在响应时会按原请求的源地址进行响应,届时客户端会直接收到来自 Node 1 的响应。对于客户端来说,请求的是 Node 2,但响应的是 Node 1,客户端很可能会丢包。故当请求离开 Node2 时,进行 SNAT,使 Node 1 的响应先转发给 Node 2,再由 Node 2 响应客户端。
综上所述,在 NodePort 模式下,其与 ClusterIP 模式下的 iptables 规则基本一致,无非是多出了 KUBE-NODEPORTS 这条处理链路。
LoadBalancer
该模式下,一般都存在一个外部的负载均衡器来配置自身为:将流量直接路由到 Service 所代理的 Endpoint 中。负载均衡器也会被分配一个外部 IP 地址,以便可以从互联网上访问该服务,这个 IP 会被记录到 Service spec 的status.loadBalancer.ingress.ip字段。
值得注意的是,并非所有外部负载均衡器都会将流量直接路由到 Endpoint 上,这取决于公有云各自的实现。以 GKE 为例,其负载均衡器都会将数据包先分发到集群的节点上,之后这些节点再将数据包路由到服务 Pod,如下图所示。
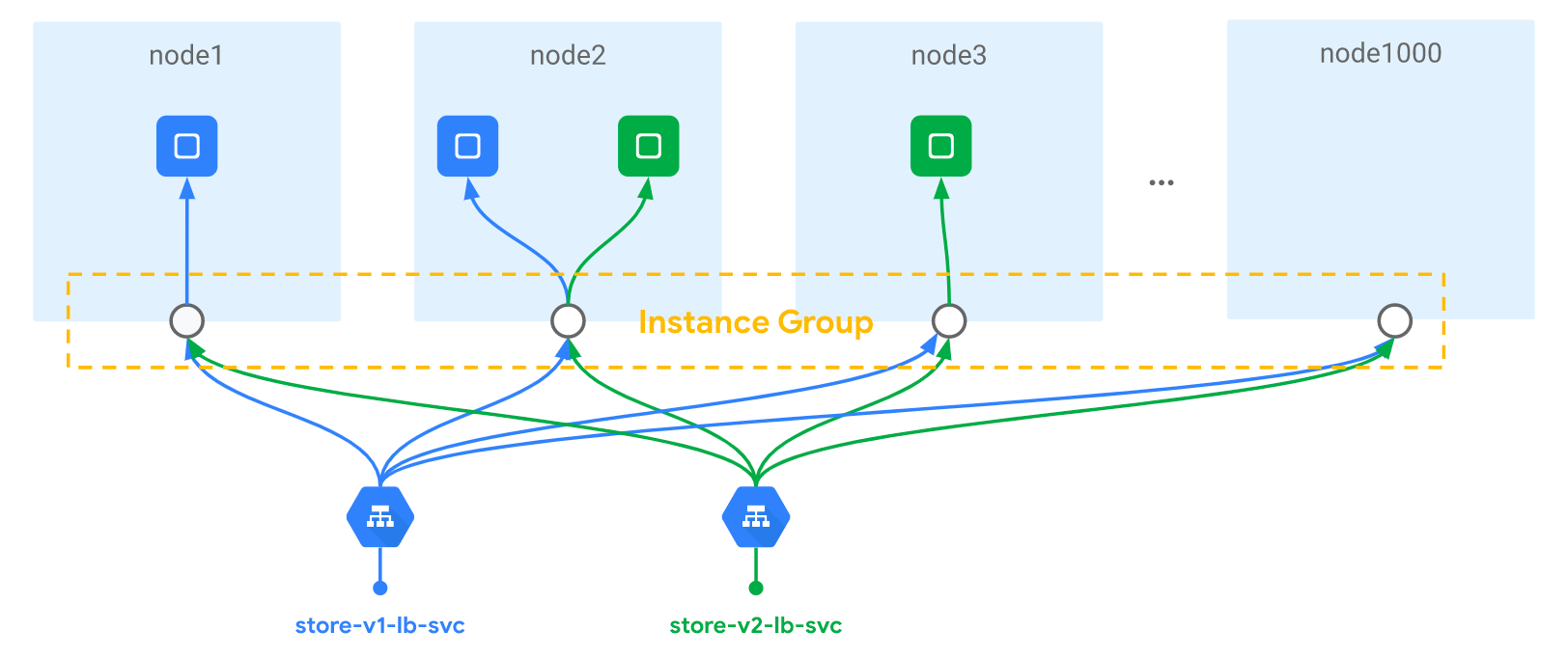
假设 Service 的 ClusterIP 为 172.30.0.41,port 为 80,使用 TCP 协议,NodePort 为 3001;另外Service.Spec.LoadBalancerSourceRanges配置为 192.168.0.0/24 和 203.0.113.0/25,该配置项用于指定可以访问该 LoadBalancer 类型 Service 的客户端地址段,该配置是否生效取决于公有云提供商是否支持(这里假设支持);LoadBalancer 的 IP 为 1.2.3.4 和 5.6.7.8;由该 Service 代理的 Endpoint 只有一个 10.180.0.1:80 。生成的 iptables 规则如下所示:
*filter
:KUBE-NODEPORTS - [0:0]
:KUBE-SERVICES - [0:0]
:KUBE-EXTERNAL-SERVICES - [0:0]
:KUBE-FORWARD - [0:0]
:KUBE-PROXY-FIREWALL - [0:0]
-A KUBE-FORWARD -m conntrack --ctstate INVALID -j DROP
-A KUBE-FORWARD -m comment --comment "kubernetes forwarding rules" -m mark --mark 0x4000/0x4000 -j ACCEPT
-A KUBE-FORWARD -m comment --comment "kubernetes forwarding conntrack rule" -m conntrack --ctstate RELATED,ESTABLISHED -j ACCEPT
-A KUBE-PROXY-FIREWALL -m comment --comment "ns1/svc1:p80 traffic not accepted by KUBE-FW-XPGD46QRK7WJZT7O" -m tcp -p tcp -d 1.2.3.4 --dport 80 -j DROP
-A KUBE-PROXY-FIREWALL -m comment --comment "ns1/svc1:p80 traffic not accepted by KUBE-FW-XPGD46QRK7WJZT7O" -m tcp -p tcp -d 5.6.7.8 --dport 80 -j DROP
COMMIT
*nat
:KUBE-NODEPORTS - [0:0]
:KUBE-SERVICES - [0:0]
:KUBE-EXT-XPGD46QRK7WJZT7O - [0:0]
:KUBE-FW-XPGD46QRK7WJZT7O - [0:0]
:KUBE-MARK-MASQ - [0:0]
:KUBE-POSTROUTING - [0:0]
:KUBE-SEP-SXIVWICOYRO3J4NJ - [0:0]
:KUBE-SVC-XPGD46QRK7WJZT7O - [0:0]
-A KUBE-NODEPORTS -m comment --comment ns1/svc1:p80 -m tcp -p tcp --dport 3001 -j KUBE-EXT-XPGD46QRK7WJZT7O
-A KUBE-SERVICES -m comment --comment "ns1/svc1:p80 cluster IP" -m tcp -p tcp -d 172.30.0.41 --dport 80 -j KUBE-SVC-XPGD46QRK7WJZT7O #2
-A KUBE-SERVICES -m comment --comment "ns1/svc1:p80 loadbalancer IP" -m tcp -p tcp -d 1.2.3.4 --dport 80 -j KUBE-FW-XPGD46QRK7WJZT7O #3
-A KUBE-SERVICES -m comment --comment "ns1/svc1:p80 loadbalancer IP" -m tcp -p tcp -d 5.6.7.8 --dport 80 -j KUBE-FW-XPGD46QRK7WJZT7O #4
-A KUBE-SERVICES -m comment --comment "kubernetes service nodeports; NOTE: this must be the last rule in this chain" -m addrtype --dst-type LOCAL -j KUBE-NODEPORTS #5
-A KUBE-EXT-XPGD46QRK7WJZT7O -m comment --comment "masquerade traffic for ns1/svc1:p80 external destinations" -j KUBE-MARK-MASQ #6
-A KUBE-EXT-XPGD46QRK7WJZT7O -j KUBE-SVC-XPGD46QRK7WJZT7O #7
-A KUBE-FW-XPGD46QRK7WJZT7O -m comment --comment "ns1/svc1:p80 loadbalancer IP" -s 192.168.0.0/24 -j KUBE-EXT-XPGD46QRK7WJZT7O #8
-A KUBE-FW-XPGD46QRK7WJZT7O -m comment --comment "ns1/svc1:p80 loadbalancer IP" -s 203.0.113.0/25 -j KUBE-EXT-XPGD46QRK7WJZT7O #9
-A KUBE-FW-XPGD46QRK7WJZT7O -m comment --comment "ns1/svc1:p80 loadbalancer IP" -s 1.2.3.4 -j KUBE-EXT-XPGD46QRK7WJZT7O #10
-A KUBE-FW-XPGD46QRK7WJZT7O -m comment --comment "ns1/svc1:p80 loadbalancer IP" -s 5.6.7.8 -j KUBE-EXT-XPGD46QRK7WJZT7O #11
-A KUBE-MARK-MASQ -j MARK --or-mark 0x4000
-A KUBE-POSTROUTING -m mark ! --mark 0x4000/0x4000 -j RETURN
-A KUBE-POSTROUTING -j MARK --xor-mark 0x4000
-A KUBE-POSTROUTING -m comment --comment "kubernetes service traffic requiring SNAT" -j MASQUERADE
-A KUBE-SEP-SXIVWICOYRO3J4NJ -m comment --comment ns1/svc1:p80 -s 10.180.0.1 -j KUBE-MARK-MASQ
-A KUBE-SEP-SXIVWICOYRO3J4NJ -m comment --comment ns1/svc1:p80 -m tcp -p tcp -j DNAT --to-destination 10.180.0.1:80
-A KUBE-SVC-XPGD46QRK7WJZT7O -m comment --comment "ns1/svc1:p80 cluster IP" -m tcp -p tcp -d 172.30.0.41 --dport 80 ! -s 10.0.0.0/8 -j KUBE-MARK-MASQ
-A KUBE-SVC-XPGD46QRK7WJZT7O -m comment --comment "ns1/svc1:p80 -> 10.180.0.1:80" -j KUBE-SEP-SXIVWICOYRO3J4NJ
COMMIT
同上一小节所述,由 KUBE-SERVICES 链 #2 开始的 ClusterIP 相关规则和 #5 最后有关 NodePort 的规则不变,KUBE-POSTROUTING 链的规则也不变。 唯一的变化是在 KUBE-SERVICES 链中,多了两条与 Load Balancer IP 相关(下面简称 LB IP)的规则 #3、#4:
- 这两条规则表明,对于访问 LB IP 的 TCP 请求,都会先将请求跳转到 KUBE-FW 相关防火墙链 #8~#11 进行处理
- KUBE-FW 防火墙链规则只会将数据包源地址符合规则的请求进行后续处理(与访问 ClusterIP 模式的服务处理一致),这里的符合规则的请求即来自于 LB 的请求或 LB 允许的客户端网段(
LoadBalancerSourceRanges);对于那些不符合规则的请求,filter 表的最后两条规则表明数据包将被丢弃
ExternalIPs
ExternalIPs 字段指定的 IP 地址必须是集群外部的 IP 地址,不能是集群内部的 IP 地址。这些 IP 地址也必须是可以被集群外部的客户端所访问的,例如公有云提供商可能为集群节点分配了公网 IP 地址。
假设 Service 的 ClusterIP 为 172.30.0.41,port 为 80,使用 TCP 协议,External IP 为 192.168.99.11;Service 代理了两个 Endpoint,其地址为 10.180.0.1:80、10.180.0.2:80,均使用 TCP 协议。生成的 iptables 规则如下所示:
*filter
:KUBE-NODEPORTS - [0:0]
:KUBE-SERVICES - [0:0]
:KUBE-EXTERNAL-SERVICES - [0:0]
:KUBE-FORWARD - [0:0]
:KUBE-PROXY-FIREWALL - [0:0]
-A KUBE-FORWARD -m conntrack --ctstate INVALID -j DROP
-A KUBE-FORWARD -m comment --comment "kubernetes forwarding rules" -m mark --mark 0x4000/0x4000 -j ACCEPT
-A KUBE-FORWARD -m comment --comment "kubernetes forwarding conntrack rule" -m conntrack --ctstate RELATED,ESTABLISHED -j ACCEPT
COMMIT
*nat
:KUBE-NODEPORTS - [0:0]
:KUBE-SERVICES - [0:0]
:KUBE-EXT-XPGD46QRK7WJZT7O - [0:0]
:KUBE-MARK-MASQ - [0:0]
:KUBE-POSTROUTING - [0:0]
:KUBE-SEP-SXIVWICOYRO3J4NJ - [0:0]
:KUBE-SEP-ZX7GRIZKSNUQ3LAJ - [0:0]
:KUBE-SVC-XPGD46QRK7WJZT7O - [0:0]
-A KUBE-SERVICES -m comment --comment "ns1/svc1:p80 cluster IP" -m tcp -p tcp -d 172.30.0.41 --dport 80 -j KUBE-SVC-XPGD46QRK7WJZT7O
-A KUBE-SERVICES -m comment --comment "ns1/svc1:p80 external IP" -m tcp -p tcp -d 192.168.99.11 --dport 80 -j KUBE-EXT-XPGD46QRK7WJZT7O #2
-A KUBE-SERVICES -m comment --comment "kubernetes service nodeports; NOTE: this must be the last rule in this chain" -m addrtype --dst-type LOCAL -j KUBE-NODEPORTS
-A KUBE-EXT-XPGD46QRK7WJZT7O -m comment --comment "masquerade traffic for ns1/svc1:p80 external destinations" -j KUBE-MARK-MASQ #4
-A KUBE-EXT-XPGD46QRK7WJZT7O -j KUBE-SVC-XPGD46QRK7WJZT7O #5
-A KUBE-MARK-MASQ -j MARK --or-mark 0x4000
-A KUBE-POSTROUTING -m mark ! --mark 0x4000/0x4000 -j RETURN
-A KUBE-POSTROUTING -j MARK --xor-mark 0x4000
-A KUBE-POSTROUTING -m comment --comment "kubernetes service traffic requiring SNAT" -j MASQUERADE
-A KUBE-SEP-SXIVWICOYRO3J4NJ -m comment --comment ns1/svc1:p80 -s 10.180.0.1 -j KUBE-MARK-MASQ
-A KUBE-SEP-SXIVWICOYRO3J4NJ -m comment --comment ns1/svc1:p80 -m tcp -p tcp -j DNAT --to-destination 10.180.0.1:80
-A KUBE-SEP-ZX7GRIZKSNUQ3LAJ -m comment --comment ns1/svc1:p80 -s 10.180.2.1 -j KUBE-MARK-MASQ
-A KUBE-SEP-ZX7GRIZKSNUQ3LAJ -m comment --comment ns1/svc1:p80 -m tcp -p tcp -j DNAT --to-destination 10.180.2.1:80
-A KUBE-SVC-XPGD46QRK7WJZT7O -m comment --comment "ns1/svc1:p80 cluster IP" -m tcp -p tcp -d 172.30.0.41 --dport 80 ! -s 10.0.0.0/8 -j KUBE-MARK-MASQ
-A KUBE-SVC-XPGD46QRK7WJZT7O -m comment --comment "ns1/svc1:p80 -> 10.180.0.1:80" -m statistic --mode random --probability 0.5000000000 -j KUBE-SEP-SXIVWICOYRO3J4NJ
-A KUBE-SVC-XPGD46QRK7WJZT7O -m comment --comment "ns1/svc1:p80 -> 10.180.2.1:80" -j KUBE-SEP-ZX7GRIZKSNUQ3LAJ
COMMIT
有关 KUBE-SERVICES 链的 ClusterIP 处理和 KUBE-POSTROUTING 的规则都不变,唯一不同是 KUBE-SERVICES 链 #2 规则:其指定了所有对于 External IP 且端口号为 80 的 TCP 请求,需先进行源地址伪装标记 #4,再通过 #5 以与 ClusterIP 相同的方式进行服务访问。
Dual stack proxier
上述都是基于 ipv4 single stack 的 proxier,对于支持 dual stack 的 proxier,其由MetaProxier表示,其中记录了 ipv4 和 ipv6 栈的 proxier。
func NewMetaProxier(ipv4Proxier, ipv6Proxier proxy.Provider) proxy.Provider {
return proxy.Provider(&metaProxier{
ipv4Proxier: ipv4Proxier,
ipv6Proxier: ipv6Proxier,
})
}
MetaProxier的具有的方法与 ipv4/6 proxier 的相同,并且也是直接调用对应 proxier 的方法。
ipvs proxier
对于 ipvs 的 proxier 来说,它与 iptables proxier 最大的不同就是在syncProxyRules方法的实现上,所以 iptables proxier 章节中除了与该方法相关的部分,其他都适用于 ipvs proxier,故不再展开赘述。syncProxyRules方法为 ipvs proxier 的核心,整个方法长达 600 行,这里不再贴出,详情可参考 pkg/proxy/ipvs/proxier.go。
当创建了 Service 之后,kp 首先会在宿主机上创建一个虚拟网卡kube-ipvs0接口,并为其分配 Service 的 ClusterIP 作为接口的 IP 地址:
_, err := proxier.netlinkHandle.EnsureDummyDevice(defaultDummyDevice) // const defaultDummyDevice => "kube-ipvs0"
if err != nil {
klog.ErrorS(err, "Failed to create dummy interface", "interface", defaultDummyDevice)
return
}
kp 通过 linux ipvs 模块,为此 IP 地址设置 Service 所代理的 Endpoint 数量个的 ipvs 虚拟主机,并设置虚拟主机之间使用轮询(可通过config.IPVS.Scheduler配置其他模式)来作为负载均衡策略。
if len(scheduler) == 0 {
klog.InfoS("IPVS scheduler not specified, use rr by default")
scheduler = defaultScheduler // => const defaultScheduler = "rr"
}
通过ipvsadm可查看 ipvs 设置:
$ ipvsadm -ln
# ...
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 10.102.128.4:80 rr # servic cluster-ip,rr => round robin
# service 代理的 pod 地址
-> 10.244.3.6:9376 Masq 1 0 0
-> 10.244.1.7:9376 Masq 1 0 0
-> 10.244.2.3:9376 Masq 1 0 0
- 任何发往 Service ClsuterIP
10.102.128.4:80的请求,都会被 ipvs 模块转发到某一个后端的 Pod 上
相比于 iptables,ipvs 在内核中的实现也是基于 netfilter 的 NAT 模式,故在转发层面,理论上没有任何性能提升。但 ipvs 并不需要在宿主机上为每个 Pod 设置 iptables 规则,而是把规则的处理下沉到了内核态,从而极大降低维护代价。
总结
kp 是 k8s 中与操作系统网络内核打交道的组件,承担了许多 k8s 服务网络底层的工作,同时也关系着集群的性能表现。长期以来 kp 在大规模集群的表现一直备受诟病,尽管从 iptables 可以升级到 ipvs,但性能提升并非出类拔萃。社区中也涌现出一批优秀的 kp 替代品,比如 Cilium 等。kp 所做的工作虽然简单,但是涉及的技术深挖起来有好多值得研究的地方,本文也只是浅尝辄止。
KEP 2104 与 kpng
从架构层面来看,kp 的 Service 与 iptables/ipvs 的实现是耦合的,这就造成了扩展 proxier 是一件很困难的操作,使 kp 的可扩展性不强、第三方开发难度较高。
KEP-2104 提出了一种重构 kp 架构的方案,并已经有了实现雏形:kpng(Kubernetes Proxy Next Generation)。kpng 将 kp 拆分为两个独立的部分:第一个部分即 frontend,负责连接 apiserver 监视并同步资源,并将资源的业务处理、计算结果通过 gRPC watchable API 提供给外界;第二个部分即 backend,通过 frontend 提供的 gRPC API 获取资源的计算结果,并进行网络的配置。这种架构就很好的将 kp 与 proxier 进行了解耦,backend 不仅可以使用 iptables/ipvs,而且也可以使用 ebpf/nftables 等网络技术,所有第三方的实现就只需关注 backend 部分即可,大大增强了 kp 的扩展性。
Reference
- https://cloudyuga.guru/hands_on_lab/k8s-qos-oomkilled
- https://kubernetes.io/docs/reference/command-line-tools-reference/kube-proxy/#options
- https://kubernetes.io/docs/concepts/services-networking/service/#ips-and-vips
- https://kubernetes.io/docs/reference/networking/virtual-ips/
- https://kubernetes.io/docs/tasks/debug/debug-application/debug-service/#is-the-kube-proxy-working
- https://github.com/kubernetes/enhancements/blob/master/keps/sig-network/3453-minimize-iptables-restore/README.md
- https://cloud.google.com/kubernetes-engine/docs/how-to/external-svc-lb-rbs
- https://kubernetes.io/docs/tasks/access-application-cluster/create-external-load-balancer/
- https://github.com/kubernetes/enhancements/pull/2094