本文代码基于 Linux Kernel v4.10 展开。
nftables(Netfilter Tables,下文简称 nft)是 linux 内核于 v3.13 引入的,意在取代传统的 xtables 工具(比如 iptables、arptables、ebtables 和 ipset 等)。nft 与它们相比,在便捷性、功能和性能上有着巨大的提升。
数据结构
开始分析 nft 之前,先自顶向下熟悉一下 nft 涉及的几种基本数据结构。
nft_table
nft 中规则集 ruleset 表示所有规则的集合,table 作为 ruleset 的顶层容器,能存储 chains、sets、stateful objects 等对象,其结构如下:
// include/net/netfilter/nf_tables.h
struct nft_table {
struct list_head list; // 内部遍历使用的参数,下同
struct list_head chains; // chains in table
struct list_head sets; // sets in table
struct list_head objects; // objects in table
u64 hgenerator; //
u32 use; // 计数,有多少 chain 引用了该 table
u16 flags:14, // nft_table_flags 的二进制位掩码
\
\
--->--- enum nft_table_flags {
NFT_TABLE_F_DORMANT = 0x1, // table 不可用
};
genmask:2; //
char name[NFT_TABLE_MAXNAMELEN]; // table name
};
在 nft 之前,xtables 被划分为了不同用户空间的工具及其对应的内核组件,以匹配 Netfilter 提供的不同组的 hooks。但在 nft 中,通过引入 Address Families(AF)的概念,从而避免了这一操作,使用户空间可以使用一个统一的工具nft。AF 有如下几种类型,并且可以被映射为不同组的 Netfilter hooks:
ip:默认类型,可映射为 ipv4 相关 hooks;NFPROTO_IPV4ip6:可映射为 ipv6 相关 hooks;NFPROTO_IPV6inet:可映射为 ipv4 和 ipv6 相关 hooks;NFPROTO_INETarp:可映射为 arp 相关 hooks;NFPROTO_ARPbridge:可映射为 bridging 相关 hooks;NFPROTO_BRIDGEnetdev:可映射为 ingress 相关 hooks;NFPROTO_NETDEV
在 nft 中,一张 table 只属于一个 AF,所以 nft ruleset 要求每个 AF 都至少存在一张 table。
nft_chain
本文只关注 nft_table 存储的 chains 对象。
nft 的规则组织在 chain 中,一条 chain 可存在多条规则。但与 xtables 不同的是,nft 不会存在任何预定义的 chain,例如 INPUT 或 OUTPUT 等。若要将 nft 的 chain 注册到 Netfilter hooks 上,则需要将 chain 创建为 base 类型,即 base chain;而对于那些由用户自定义创建的,不经过内核 TCP/IP 栈的 chain,则称之为 regular chain。regular chain 本身并不会看到任何网络流量,但可以从 base chain 跳转至 regular chain 配合使用。
nft 中 chain 的实现结构如下,规则在 chain 中是以双向链表的形式组织的。
// include/net/netfilter/nf_tables.h
struct nft_chain {
struct list_head rules; // 规则链表
struct list_head list;
struct nft_table *table; // 所属 table
u64 handle; //
u32 use; // 计数,有多少 chain 可以跳转过来
u16 level; //
u8 flags:6, // nft_chain_flags 的二进制位掩码
\
\
--->--- enum nft_chain_flags {
NFT_BASE_CHAIN = 0x1, // base chain
};
genmask:2; //
char name[NFT_CHAIN_MAXNAMELEN]; // chain name
};
特别地,base chain 的结构虽然是对 chain 的再度封装,但也涉及了另外两个概念:类型(type)和策略(policy)。对于后者来说,它规定了当一个数据包来到 chain 末尾时的行为。
struct nft_base_chain {
struct nf_hook_ops ops[NFT_HOOK_OPS_MAX]; // hooks 函数
const struct nf_chain_type *type; // chain 类型
\
\
--->--- struct nf_chain_type {
const char *name; // 类型的名称
enum nft_chain_type type; // 类型的枚举值
\
\
--->--- enum nft_chain_type {
NFT_CHAIN_T_DEFAULT = 0, // filter 类型,默认
NFT_CHAIN_T_ROUTE, // route 类型
NFT_CHAIN_T_NAT, // nat 类型
NFT_CHAIN_T_MAX
};
int family; // address family, AF
struct module *owner; // 所属模块
unsigned int hook_mask; // 生效的 hooks
nf_hookfn *hooks[NF_MAX_HOOKS]; // hooks 函数,会覆盖上述的 hooks 函数
};
u8 policy; // chain 的策略,目前只有两个:accept(默认)或 drop
u8 flags;
struct nft_stats __percpu *stats; // 统计信息
struct nft_chain chain; // 所属的 chain
char dev_name[IFNAMSIZ]; // base chain 所关联的设备名称,可选值
};
nft_rule
nft chain 中的每条规则都包含 0 或多个 expression(expr),及 1 或多个 statements(stmt)。expr 用于匹配数据包是否含有指定的字段或元数据,expr 之间按照规则声明的顺序,从左到右依次执行。只有当一个数据包通过了所有 expr 检查之后,才会去执行 stmt。每个 stmt 都对应一个动作,例如跳转到其他 chain、设置 netfilter 标记、数据包计数等,与 expr 相同,stmt 也是从左到右依次执行。
nft chain 中存储的规则使用nft_rule结构体描述:
// include/net/netfilter/nf_tables.h
struct nft_rule {
struct list_head list;
u64 handle:42, //
genmask:2, //
dlen:12, // 规则长度
udata:1; // 规则中是否含有用户数据
unsigned char data[]; // 存储 nft_expr 的数组
}; \
\
--->-- struct nft_expr {
const struct nft_expr_ops *ops;
unsigned char data[]; // expr 所用到的数据
};
nft_expr_ops规定了实现每个 expr 所需函数的指针,涉及 expr 的执行(eval)、初始化(init)、验证(validate)等操作:
struct nft_expr_ops {
void (*eval)(const struct nft_expr *expr, // 执行
struct nft_regs *regs,
const struct nft_pktinfo *pkt);
int (*clone)(struct nft_expr *dst, // 复制
const struct nft_expr *src);
unsigned int size; // expr 整体的大小
int (*init)(const struct nft_ctx *ctx, // 初始化
const struct nft_expr *expr,
const struct nlattr * const tb[]);
void (*destroy)(const struct nft_ctx *ctx, // 销毁
const struct nft_expr *expr);
int (*dump)(struct sk_buff *skb, // 显示参数
const struct nft_expr *expr);
int (*validate)(const struct nft_ctx *ctx,// 验证
const struct nft_expr *expr,
const struct nft_data **data);
const struct nft_expr_type *type; // expr 类型
void *data; // 与该 expr 相关联的额外数据
};
struct nft_expr_type {
const struct nft_expr_ops *(*select_ops)(const struct nft_ctx *,
const struct nlattr * const tb[]);
const struct nft_expr_ops *ops;
struct list_head list;
const char *name; // expr 的标识符
// ...
u8 family; // address family, AF
u8 flags;
};
核心概念: Address Families
注意,在 AF 中描述的所有 chain 类型,都是针对 base chain 展开的。
AF 的抽象是 nft 灵活性的本质。在 nft 的基础定义中,可以看到它所支持的 AF 类型(与前文描述一致),每种类型都由nft_af_info描述:
// include/net/netns/nftables.h
struct netns_nftables {
struct list_head af_info;
struct list_head commit_list;
struct nft_af_info *ipv4;
struct nft_af_info *ipv6;
struct nft_af_info *inet;
struct nft_af_info *arp;
struct nft_af_info *bridge;
struct nft_af_info *netdev;
unsigned int base_seq;
u8 gencursor;
};
// include/net/netfilter/nf_tables.h
struct nft_af_info {
struct list_head list;
int family; // address familiy, AF
unsigned int nhooks; // 此 AF 中 hooks 的数量
struct module *owner;
struct list_head tables; // 所包含的 table
u32 flags;
unsigned int nops; // 此 AF 中 hook ops 的数量
void (*hook_ops_init)(struct nf_hook_ops *, // hook ops 初始化函数
unsigned int);
nf_hookfn *hooks[NF_MAX_HOOKS]; // 注册的 hooks 函数
};
下面对部分 AF 类型展开分析,主要讨论 AF 与 Netfilter hooks 之间的映射关系,关于它们间类型完整的映射关系,可参考此处。
ipv4
ipv4 对应的 AF 类型通过nf_tables_ipv4_init向内核注册,可以发现 ipv4 类型的 chain 可以映射到 ipv4 相关的所有 Netfilter hooks 上。
// net/ipv4/netfilter/nf_tables_ipv4.c
static int __init nf_tables_ipv4_init(void)
{
int ret;
// 注册 ipv4 chain 类型
ret = nft_register_chain_type(&filter_ipv4);
if (ret < 0) |
return ret; |
| --->--- static const struct nf_chain_type filter_ipv4 = {
.name = "filter",
.type = NFT_CHAIN_T_DEFAULT, // filter type chain
.family = NFPROTO_IPV4, // AF
.owner = THIS_MODULE,
.hook_mask = (1 << NF_INET_LOCAL_IN) |
(1 << NF_INET_LOCAL_OUT) |
(1 << NF_INET_FORWARD) |
(1 << NF_INET_PRE_ROUTING) |
(1 << NF_INET_POST_ROUTING),
};
// 向网络命名空间子系统注册 nft ipv4 相关信息
ret = register_pernet_subsys(&nf_tables_ipv4_net_ops);
if (ret < 0) |
nft_unregister_chain_type(&filter_ipv4); |
|
static struct pernet_operations nf_tables_ipv4_net_ops = {
.init = nf_tables_ipv4_init_net, ->--
.exit = nf_tables_ipv4_exit_net, \
}; \
return ret; memcpy(net->nft.ipv4, &nft_af_ipv4);
} nft_register_afinfo(net, net->nft.ipv4)
/
/
// AF info /
struct nft_af_info nft_af_ipv4 __read_mostly = { // -------<-------
.family = NFPROTO_IPV4,
.nhooks = NF_INET_NUMHOOKS,
.owner = THIS_MODULE,
.nops = 1,
.hooks = {
[NF_INET_LOCAL_IN] = nft_do_chain_ipv4,
[NF_INET_LOCAL_OUT] = nft_ipv4_output,
[NF_INET_FORWARD] = nft_do_chain_ipv4,
[NF_INET_PRE_ROUTING] = nft_do_chain_ipv4,
[NF_INET_POST_ROUTING] = nft_do_chain_ipv4,
},
};
除此之外,ipv4 还注册了 nat 和 route 类型的 chain。nat 类型的 chain 能映射到除了NF_INET_FORWARD之外的所有 Netfilter hooks 上,而 route 类型的 chain 只能映射到NF_INET_LOCAL_OUT这一个 Netfilter hook 上。
// net/ipv4/netfilter/nft_chain_nat_ipv4.c
static const struct nf_chain_type nft_chain_nat_ipv4 = {
.name = "nat",
.type = NFT_CHAIN_T_NAT, // nat type
.family = NFPROTO_IPV4,
.owner = THIS_MODULE,
.hook_mask = (1 << NF_INET_PRE_ROUTING) |
(1 << NF_INET_POST_ROUTING) |
(1 << NF_INET_LOCAL_OUT) |
(1 << NF_INET_LOCAL_IN),
.hooks = {
[NF_INET_PRE_ROUTING] = nft_nat_ipv4_in,
[NF_INET_POST_ROUTING] = nft_nat_ipv4_out,
[NF_INET_LOCAL_OUT] = nft_nat_ipv4_local_fn,
[NF_INET_LOCAL_IN] = nft_nat_ipv4_fn,
},
};
// net/ipv4/netfilter/nft_chain_route_ipv4.c
static const struct nf_chain_type nft_chain_route_ipv4 = {
.name = "route",
.type = NFT_CHAIN_T_ROUTE, // route type
.family = NFPROTO_IPV4,
.owner = THIS_MODULE,
.hook_mask = (1 << NF_INET_LOCAL_OUT),
.hooks = {
[NF_INET_LOCAL_OUT] = nf_route_table_hook,
},
};
arp
arp 类型使用nf_tables_arp_init向内核注册,该函数工作与上文一致,这里不再展开赘述(下文也是);注册该 chain 的类型为 filter,该类型同样可以映射到 arp 相关的所有 Netfilter hooks 上。
// net/ipv4/netfilter/nf_tables_arp.c
static struct nft_af_info nft_af_arp __read_mostly = {
.family = NFPROTO_ARP,
.nhooks = NF_ARP_NUMHOOKS,
.owner = THIS_MODULE,
.nops = 1,
.hooks = {
[NF_ARP_IN] = nft_do_chain_arp,
[NF_ARP_OUT] = nft_do_chain_arp,
[NF_ARP_FORWARD]= nft_do_chain_arp,
},
};
bridge
bridge 类型的 chain type 同样也是 filter,并且可以映射到 bridge 相关的所有 Netfilter hooks 上:
// net/bridge/netfilter/nf_tables_bridge.c
static struct nft_af_info nft_af_bridge __read_mostly = {
.family = NFPROTO_BRIDGE,
.nhooks = NF_BR_NUMHOOKS,
.owner = THIS_MODULE,
.nops = 1,
.hooks = {
[NF_BR_PRE_ROUTING] = nft_do_chain_bridge,
[NF_BR_LOCAL_IN] = nft_do_chain_bridge,
[NF_BR_FORWARD] = nft_do_chain_bridge,
[NF_BR_LOCAL_OUT] = nft_do_chain_bridge,
[NF_BR_POST_ROUTING] = nft_do_chain_bridge,
},
};
netdev
netdev 类型是整个 AF 中最与众不同的一个类型,它用于创建能够关联单个网络接口的 base chain,而且这个 base chain 能够看到该网络接口上的所有流量。netdev 类型的 chain 只会被映射到NF_NETDEV_INGRESS这一个 Netfilter hook 上,这个 ingress hook 是于 linux kernel v4.2 引入的,hook 所处位置如下图所示(图片来源链接)。
// net/netfilter/nf_tables_netdev.c
static const struct nf_chain_type nft_filter_chain_netdev = {
.name = "filter",
.type = NFT_CHAIN_T_DEFAULT, // filter type
.family = NFPROTO_NETDEV,
.owner = THIS_MODULE,
.hook_mask = (1 << NF_NETDEV_INGRESS),
};
static struct nft_af_info nft_af_netdev __read_mostly = {
.family = NFPROTO_NETDEV,
.nhooks = NF_NETDEV_NUMHOOKS,
.owner = THIS_MODULE,
.flags = NFT_AF_NEEDS_DEV,
.nops = 1,
.hooks = {
[NF_NETDEV_INGRESS] = nft_do_chain_netdev,
},
};
ingress chain 能够看到刚由 NIC 驱动处理完就传入网络内核栈的数据包,这种处于包路径最开始位置的 chain 最适合做 DDoS 防御,可直接将数据包丢弃。相比传入 PREROUTING 后再丢包,能提升两倍的性能。值得注意的是,在 ingress chain 中分片的数据报还没有被重组。这虽然对于匹配数据包的 IP 源地址和目的地址没有影响,但是对于匹配 L4 header 比如 udp port 就只对未分片的数据包或已分片数据包的第一个有效。
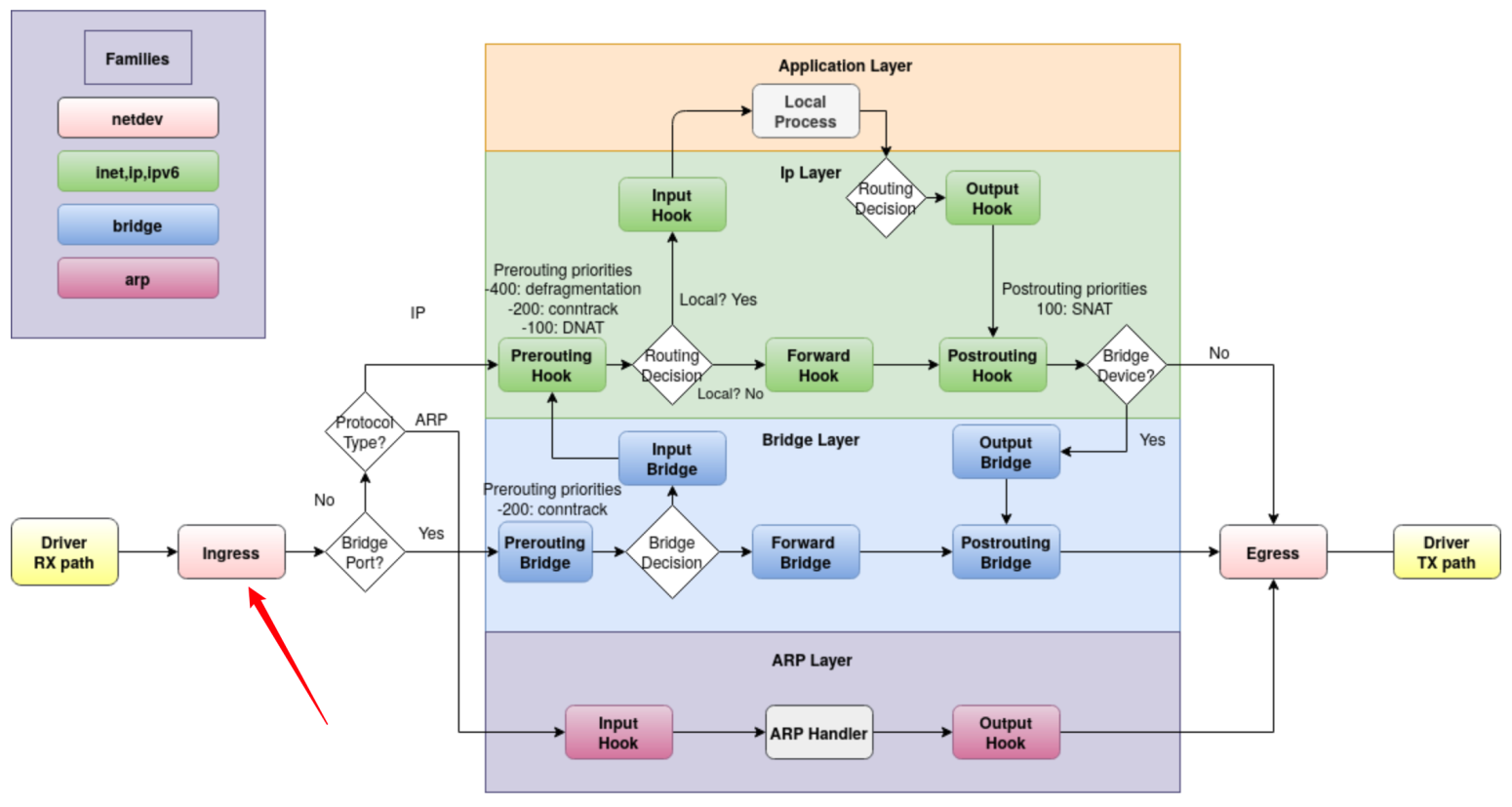
netdev AF 除了向内核注册 chain 类型和 AF 信息之外,还通过register_netdevice_notifier(&nf_tables_netdev_notifier)向内核注册了notifier_call的回调函数,用于接收各种网络接口设备的事件,并对该网络接口设备关联的 base chain 进行处理。该回调函数如下所示,其只处理网络接口设备注销(NETDEV_UNREGISTER)和接口重命名(NETDEV_CHANGENAME)两种事件。对于前者,会删除对应该设备的 base chain;对于后者,则会记录设备的新名称到 base chain。
// net/netfilter/nf_tables_netdev.c
static int nf_tables_netdev_event(struct notifier_block *this, unsigned long event, void *ptr)
{
struct net_device *dev = netdev_notifier_info_to_dev(ptr); // ptr->dev
struct nft_af_info *afi;
struct nft_table *table;
struct nft_chain *chain, *nr;
struct nft_ctx ctx = {
.net = dev_net(dev),
};
if (event != NETDEV_UNREGISTER && event != NETDEV_CHANGENAME)
return NOTIFY_DONE;
nfnl_lock(NFNL_SUBSYS_NFTABLES);
// 遍历找到类型为 netdev 的 AF
list_for_each_entry(afi, &dev_net(dev)->nft.af_info, list) {
ctx.afi = afi;
if (afi->family != NFPROTO_NETDEV)
continue;
// 遍历 netdev AF 下的每个 table
list_for_each_entry(table, &afi->tables, list) {
ctx.table = table;
// 只处理该 table 下的 base chain 类型
list_for_each_entry_safe(chain, nr, &table->chains, list) {
if (!(chain->flags & NFT_BASE_CHAIN))
continue;
ctx.chain = chain;
nft_netdev_event(event, dev, &ctx); // 事件处理
}
}
}
nfnl_unlock(NFNL_SUBSYS_NFTABLES);
return NOTIFY_DONE;
}
static void nft_netdev_event(unsigned long event, struct net_device *dev, struct nft_ctx *ctx)
{
struct nft_base_chain *basechain = nft_base_chain(ctx->chain);
switch (event) {
case NETDEV_UNREGISTER:
if (strcmp(basechain->dev_name, dev->name) != 0) // 确保设备名对应正确
return;
__nft_release_basechain(ctx); // 删除该 base chain
break;
case NETDEV_CHANGENAME:
if (dev->ifindex != basechain->ops[0].dev->ifindex) // 确保设备序号对应正确
return;
strncpy(basechain->dev_name, dev->name, IFNAMSIZ); // 拷贝新的设备名
break;
}
}
核心工作: nft_do_chain
关于 nft 的 API 操作接口以及 nft 规则的各种 expr 类型并非本文关注的重点,具体可查看 net/netfilter/nf_tables_api.c 和此篇博客。
在上文中,各种 AF 尽管向内核 hooks 注册了不同的回调函数,但它们本质上的工作都是一样的:先通过nft_set_pktinfo从 skb_buff 中收集数据包相关的信息(L3 之前的 hooks 中还要进行 ipv4/ipv6 的头部校验,arp 除外),再调用nft_do_chain开启 chain 的执行。nft_do_chain的函数内容如下(省略了 trace 和 stats 的相关代码):
// net/netfilter/nf_tables_core.c
unsigned int nft_do_chain(struct nft_pktinfo *pkt, void *priv)
{
const struct nft_chain *chain = priv, *basechain = chain;
const struct nft_rule *rule;
const struct nft_expr *expr, *last;
struct nft_regs regs;
unsigned int stackptr = 0;
struct nft_jumpstack jumpstack[NFT_JUMP_STACK_SIZE];
int rulenum; // chain 中 rule 的计数
// ...
do_chain:
rulenum = 0;
// 让 nft_rule.list 字段指向 chain->rules,以供下述遍历使用
rule = list_entry(&chain->rules, struct nft_rule, list);
next_rule:
regs.verdict.code = NFT_CONTINUE;
// 遍历 chain 中的每一个 rule
list_for_each_entry_continue_rcu(rule, &chain->rules, list) {
// 对于没有生效的 rule,则直接跳过
if (unlikely(rule->genmask & gencursor)) continue;
rulenum++;
// 遍历 rule 中的每一个 expr 并执行
nft_rule_for_each_expr(expr, last, rule) {
// ...
expr->ops->eval(expr, ®s, pkt);
// 若其中有一个 expr 执行失败,则不再继续执行
if (regs.verdict.code != NFT_CONTINUE) break;
}
switch (regs.verdict.code) {
case NFT_BREAK:
// nft 的 chain 允许断点,对于断点仍可继续执行
regs.verdict.code = NFT_CONTINUE;
continue;
case NFT_CONTINUE:
// 继续执行
// ...
continue;
}
// 有 rule 执行失败,则退出 chain
break;
}
// 处理 base chain 的 verdict 状态,其状态枚举值与 Netfilter 的一致
switch (regs.verdict.code & NF_VERDICT_MASK) {
case NF_ACCEPT:
case NF_DROP:
case NF_QUEUE:
case NF_STOLEN:
return regs.verdict.code;
}
// 处理 regular chain 的 verdict 状态
switch (regs.verdict.code) {
case NFT_JUMP:
// 对于有跳转的 chain,则记录原 chain 到跳转栈
jumpstack[stackptr].chain = chain;
jumpstack[stackptr].rule = rule;
jumpstack[stackptr].rulenum = rulenum;
stackptr++;
/* fall through */
case NFT_GOTO:
// 并再次执行跳转到的 chain
chain = regs.verdict.chain;
goto do_chain;
case NFT_CONTINUE:
rulenum++;
/* fall through */
case NFT_RETURN:
break;
}
// 若跳转到的 chain 已经执行完了,则再跳回到原来的 chain 继续执行
if (stackptr > 0) {
stackptr--;
chain = jumpstack[stackptr].chain;
rule = jumpstack[stackptr].rule;
rulenum = jumpstack[stackptr].rulenum;
goto next_rule;
}
// ...
// 当抵达 base chain 的末尾时,根据其 policy 来决定数据包的去留
return nft_base_chain(basechain)->policy;
}
上文所描述的各种 hooks 回调函数的工作,主要是针对 chain 类型为 filter 的 AF 展开。在 ipv4 AF 中,涉及到的 nat 与 route 类型的 chain,它们在 hooks 上处理方式稍微不同。
对于 route 类型的 chain 来说,它一般在 OUTPUT 位置上的 hook 生效,其回调函数工作与上述唯一不同的地方在于,数据包在头部相关字段值被修改时会被重新路由。有关重新路由的ip_route_me_harder方法实现,这里不做展开,具体可参考 net/ipv4/netfilter.c。
// net/ipv4/netfilter/nft_chain_route_ipv4.c
static unsigned int nf_route_table_hook(void *priv,
struct sk_buff *skb,
const struct nf_hook_state *state)
{
// ...
// 获取数据包信息
nft_set_pktinfo_ipv4(&pkt, skb, state);
mark = skb->mark;
iph = ip_hdr(skb);
saddr = iph->saddr;
daddr = iph->daddr;
tos = iph->tos;
// 在执行完 chain 之后,对于 base chain 返回的 verdict 结果
ret = nft_do_chain(&pkt, priv);
if (ret != NF_DROP && ret != NF_STOLEN) {
// 若非丢弃或被窃取,并且 ip header 地址发生了改变,则修改 sk_buff 的路由结果值
iph = ip_hdr(skb);
if (iph->saddr != saddr ||
iph->daddr != daddr ||
skb->mark != mark ||
iph->tos != tos) {
err = ip_route_me_harder(state->net, skb, RTN_UNSPEC);
if (err < 0)
ret = NF_DROP_ERR(err);
}
}
return ret;
}
对于 nat 类型的 chain 来说,在每个 hooks 的函数中,nft_do_chain都不是被直接调用的,而是作为回调函数指针do_chain传入nf_nat_ipv4_fn函数使用的。nf_nat_ipv4_fn是 Netfilter 中各个 hooks 执行时所调用的函数,是 NAT 的核心方法。在该函数中,do_chain只有在从未经过 SNAT/DNAT 时才会被执行:
// net/ipv4/netfilter/nf_nat_l3proto_ipv4.c
unsigned int
nf_nat_ipv4_fn(void *priv, struct sk_buff *skb,
const struct nf_hook_state *state,
unsigned int (*do_chain)(void *priv,
struct sk_buff *skb,
const struct nf_hook_state *state,
struct nf_conn *ct))
{
// ...
ct = nf_ct_get(skb, &ctinfo);
// 对于没有连接追踪或连接追踪丢失的数据包,不进行 NAT
if (!ct) return NF_ACCEPT;
if (nf_ct_is_untracked(ct)) return NF_ACCEPT;
switch (ctinfo) {
case IP_CT_RELATED:
case IP_CT_RELATED_REPLY:
// ...
case IP_CT_NEW:
if (!nf_nat_initialized(ct, maniptype)) {
unsigned int ret;
ret = do_chain(priv, skb, state, ct); // 执行 nft_do_chain
if (ret != NF_ACCEPT) return ret;
// ...
} else { /* ... */ }
break;
// ...
}
// 对数据包进行 NAT 变换
return nf_nat_packet(ct, ctinfo, state->hook, skb);
}
应用
kube-proxy with nft
之前的文章提到过,kpng 可以扩展 kube-proxy 的 proxier 实现,本文就以 kpng 实现的 nft backend 为例,分析一下 nft 模式下的 kube-proxy 该如何工作。
假设存在一个 Service,ClusterIP 为 10.96.0.1,端口为 443/TCP,其代理了一个 Endpoint,地址为 172.18.0.4:6443;在 kube-system 下,还存在 kube-dns 的 Service,其 ClusterIP 为 10.96.0.10,可用端口号有 53/UDP,53/TCP,9153/TCP。如下是 kpng nft backend 生成规则的 ip 表部分:
- 该表中有声明了 5 个 base chain(#a~#e),其中在所有数据包流入方向进行 DNAT(#c、#d),并在出方向对所有非本地数据包进行源地址伪装(#e)
- 对于 DNAT,则跳转至
z_dnat_all的 regular chain 执行,如 #1~#5 所示。请求会通过随机策略的负载均衡路由到一个 Endpoint 地址,Service 的每个 Endpoint 都会是一个单独的 chain,用于执行各自的 DNAT
- 对于 DNAT,则跳转至
- 当然还在转发(#a)和流出方向(#b),声明了 filter 类型的 chain:
z_filter_all,用于过滤到 kube-dns 的请求(#6~#8)
table ip k8s_svc {
chain svc_default_kubernetes_ep_ac120004 { // #5,endpoint
tcp dport 443 dnat to 172.18.0.4:6443
}
chain svc_default_kubernetes_dnat { // #3,DNAT
tcp dport 443 jump svc_default_kubernetes_eps
}
chain svc_default_kubernetes_eps { // #4,随机策略的负载均衡
numgen random mod 1 vmap {
0: jump svc_default_kubernetes_ep_ac120004 }
}
chain svc_kube-system_kube-dns_filter { // #8
udp dport 53 reject
tcp dport 53 reject
tcp dport 9153 reject
}
chain z_dispatch_svc_dnat { // #2
ip daddr vmap {
10.96.0.1: jump svc_default_kubernetes_dnat }
}
chain z_dispatch_svc_filter { // #7
ip daddr vmap {
10.96.0.10: jump svc_kube-system_kube-dns_filter }
}
chain z_dnat_all { // #1
jump z_dispatch_svc_dnat
}
chain z_filter_all { // #6
ct state invalid drop
jump z_dispatch_svc_filter
}
// base chain
chain z_hook_filter_forward { // #a
type filter hook forward priority 0;
jump z_filter_all
}
chain z_hook_filter_output { // #b
type filter hook output priority 0;
jump z_filter_all
}
chain z_hook_nat_output { // #c
type nat hook output priority 0;
jump z_dnat_all
}
chain z_hook_nat_prerouting { // #d
type nat hook prerouting priority 0;
jump z_dnat_all
}
chain zz_hook_nat_postrouting { // #e
type nat hook postrouting priority 0;
# masquerade non-cluster traffic to non-local endpoints
ip saddr != { 0.0.0.0/0 } fib daddr type != local masquerade
}
}
// ip6 table 略
load balancing with nft
nft 针对负载均衡,引入两个 expr:nft_numgen和nft_hash,前者负责生成数字,后者则是一致性哈希算法的实现。
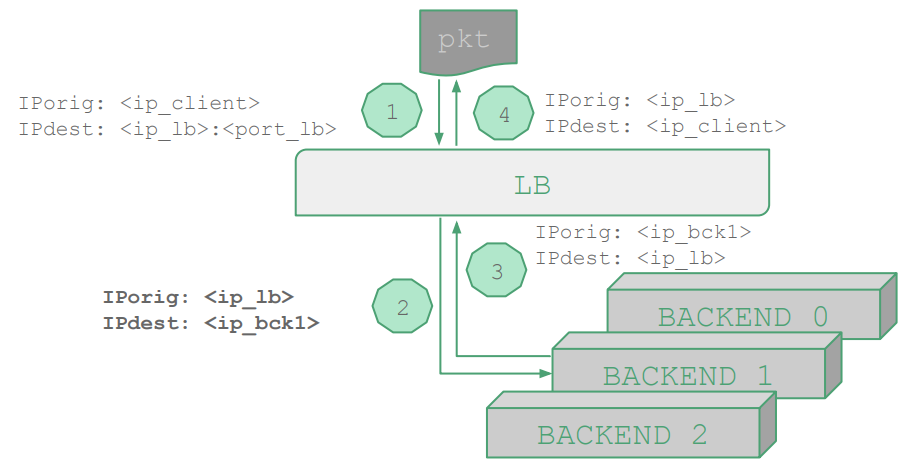
对于一个使用 SNAT 拓扑的 LB(如上图所示),其请求方向的 nft 规则如下所示;LB 会将请求 DNAT 到一个后端,后端则会将响应发送至 LB,再由 LB 转发到客户端。值得注意的是,负载均衡规则中的那些后端地址,可以是硬编码的,即 stateless NAT;相比 stateful NAT,可省去连接追踪的过程。
table ip nat {
chain prerouting {
type nat hook prerouting priority 0; policy accept;
# 匹配到达 LB 的请求,则使用轮询负载均衡策略,返回到一个后端
ip daddr <ip_lb> tcp dport <port_lb> dnat to numgen inc mod 3 map { \
0 : <ip_bck0>, \
1 : <ip_bck1>, \
2 : <ip_bck2> }
}
chain postrouting {
type nat hook postrouting priority 100; policy accept;
masquerade # 源地址伪装,伪装为 LB 的 IP
}
}
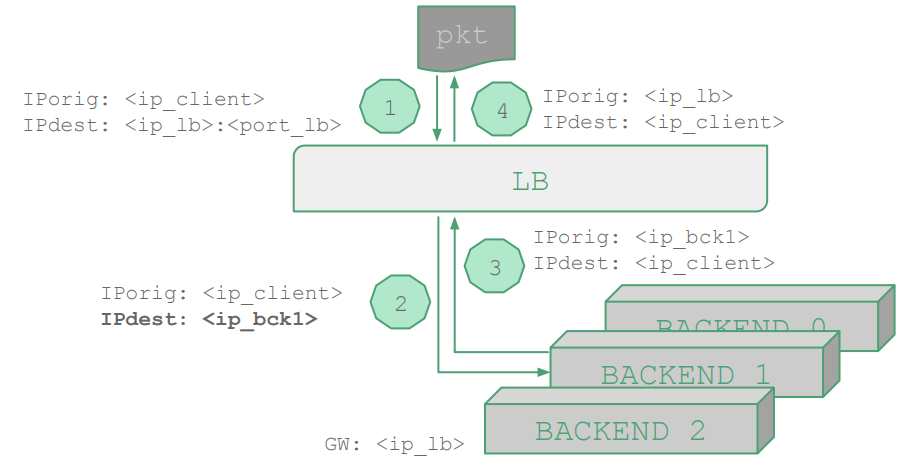
对于一个使用 DNAT 拓扑的 LB(如上图所示),其请求方向的 nft 规则如下所示;LB 会将请求 DNAT 到一个后端,后端的响应仍需经过 LB 做源地址伪装后,才能到达客户端。
table ip nat {
chain prerouting {
type nat hook prerouting priority 0; policy accept;
# 匹配到 LB 的请求,则使用随机负载均衡策略,返回到一个后端
ip daddr <ip_lb> tcp dport <port_lb> dnat to numgen random mod 3 map { \
0 : <ip_bck0>, \
1 : <ip_bck1>, \
2 : <ip_bck2> }
}
chain postrouting {
type nat hook postrouting priority 100; policy accept;
}
}
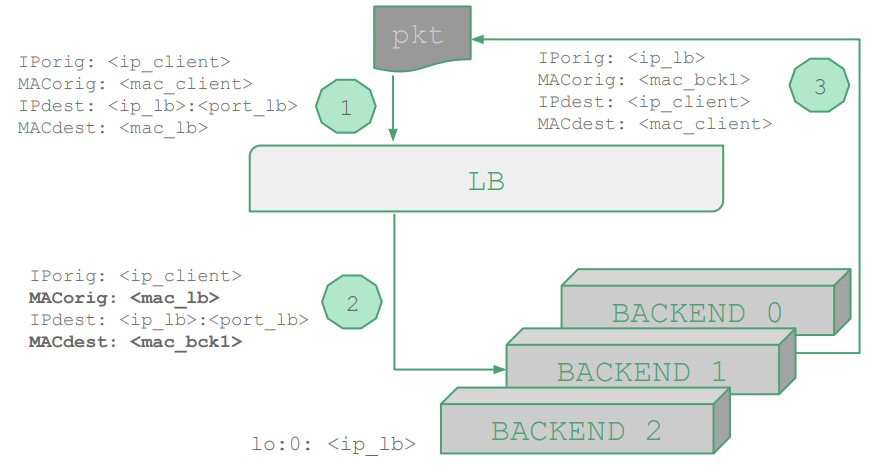
对于一个使用 DSR 拓扑的 LB(如上图所示),其 nft 规则如下所示;在 LB 网络接口的 ingress hook 处,将目的地址和目的端口为 LB 的请求,置其源二层地址为 LB 的二层地址,目的二层地址为一后端二层地址;对于后端的响应,可直接通过客户端的 IP 地址和 MAC 地址进行返回。
table netdev filter {
chain ingress {
type filter hook ingress device <if_lb> priority 0; policy accept;
# 指定随机种子的哈希负载均衡策略
ip daddr <ip_lb> tcp dport <port_lb> ether saddr set <mac_lb> \
ether daddr set jhash ip saddr . tcp sport mod 3 seed 0xabcd \
map { \
0: <mac_bck0>, \
1: <mac_bck1>, \
2: <mac_bck2> } \
fwd to <if_lb>
}
}
总结
nft 不算是一个新技术,其存在于 linux 内核已有 3 个版本了,但是提到它,大家还是比较陌生。nft 虽然是个精心雕琢的数据包过滤机制,但在将它合并进内核时,就引发过一些争议:iptables 现已在广泛使用,替换它会破坏现有用户空间的 API 也会破坏现存的 iptables 规则。所以很长时间,iptables 和 nft 是共存的。
nft 与 iptables 最大的一个不同就是:没有任何协议知识上的实现。iptables 是基于协议知识来实现的,这就造成了在实现不同协议时,iptables 存在了许多重复的代码(比如提取端口号等)。不仅如此,iptables 对于不同协议,其能力和使用语法也各不相同。本文说到 nft 是通过引入 AF 机制来增加其使用上的灵活性,仔细思考,其实就是将协议知识由内核空间移动到了用户空间,这样针对所有协议的处理,一个nft_do_chain函数就直接搞定,很大程度上简化了内核代码。
Reference
- https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/8/html/configuring_and_managing_networking/getting-started-with-nftables_configuring-and-managing-networking
- https://wiki.nftables.org/wiki-nftables/index.php
- https://zasdfgbnm.github.io/2017/09/07/Extending-nftables/
- https://thermalcircle.de/doku.php?id=blog:linux:nftables_packet_flow_netfilter_hooks_detail
- https://legacy.netdevconf.info/1.2/slides/oct6/08_nftables_Load_Balancing_with_nftables_II_Slides.pdf
- https://lwn.net/Articles/324989/
- https://lwn.net/Articles/324251/