本文代码基于 MetalLB v0.13.9 展开。
MetalLB 是一个基于标准路由协议的,用于裸机(bare-metal)k8s 集群的负载均衡器。这里裸机是指,直接部署的 k8s 集群并不能使用 LoadBalancer 类型的 Service,因为它没有提供一种负载均衡器的实现,只有在一些云服务 IaaS 平台(例如 AWS、GCP 等)上才能使用。
MetalLB 从两个方面实现了这么一个负载均衡器:地址分配(Address Allocation)和外部广播(External Announcement)。
地址分配
类似于各种云厂商的实现,对每个向负载均衡器的请求分配 IP 地址。MetalLB 则负责在裸机集群中分配 IP 地址,这个 IP 地址是从预先配置的地址池(AddressPool)中获取的;同样当 Service 被删除后,MetalLB 也负责回收该地址。
核心方法
reconcileService
此方法是 service-controller 的调协方法,位于 MetalLB 的 controller 组件中,负责监听所有类型的 Service,然后对它们的 IP 地址进行管理(分配或回收)。
// internal/k8s/controllers/service_controller.go
func (r *ServiceReconciler) reconcileService(ctx context.Context, req ctrl.Request) (ctrl.Result, error) {
// ...
var service *v1.Service
// 根据 Endpoint 提供的 NamespacedName 对象寻找对应的 Service 对象
service, err := r.serviceFor(ctx, req.NamespacedName)
if err != nil { \
return ctrl.Result{}, err \
} -->-- r.Get(ctx, name, &res)
// 若 MetalLB 的配置文件中指定了 LoadBalancerClass,则比对它和 Service 的是否一致
// 只有一致或无指定配置时才可通过,默认情况下,配置文件不指定该字段
if filterByLoadBalancerClass(service, r.LoadBalancerClass) {
return ctrl.Result{}, nil
}
// 根据 Service 获取其所代理的 Endpoints 或 EndpointSlice
epSlices, err := epsOrSlicesForServices(ctx, r, req.NamespacedName, r.Endpoints)
if err != nil {
return ctrl.Result{}, err
}
// 此时根据 Service 是否为空,可以判断出此次调谐是对 Service 的删除还是更新
// 对 Service 进行处理,包括 IP 地址的分配和回收
res := r.Handler(r.Logger, req.NamespacedName.String(), service, epSlices)
switch res {
case SyncStateError:
return ctrl.Result{}, retryError
case SyncStateReprocessAll:
// 重新进行全量的调谐
r.forceReload()
return ctrl.Result{}, nil
case SyncStateErrorNoRetry:
return ctrl.Result{}, nil
}
return ctrl.Result{}, nil
}
Service Controller 调谐所使用的更新数据是一个ctrl.Request类型的更新请求,这个更新请求是跟随 MetalLB controller 组件中 manager 的第一个Watches方法创建的,此方法监听所有 Service 类型的资源,并提取其所代理 Endpoints 的命名空间和名字,形成一个内容为NamespacedName的ctrl.Request更新请求。
ctrl.NewControllerManagedBy(mgr).
For(&v1.Service{}).
Watches(&source.Kind{Type: &v1.Endpoints{}},
handler.EnqueueRequestsFromMapFunc(func(obj client.Object) []reconcile.Request {
endpoints, ok := obj.(*v1.Endpoints)
if !ok {
return []reconcile.Request{}
}
name := types.NamespacedName{Name: endpoints.Name, Namespace: endpoints.Namespace}
return []reconcile.Request
})).
Watches(&source.Channel{Source: r.Reload}, &handler.EnqueueRequestForObject{}).
Complete(r)
不难发现,除了第一个Watches方法的资源监控,Service Controller 还注册了第二个Watches方法:即监听所有 Reload 事件。Reload 事件即全量的对 Service 进行调谐(与上述r.forceReload()相同),这里监听Reload通道是为了方便在代码其他逻辑中可以触发全量调谐。除此之外,将第一个Watches方法监听到的资源也转换为了一个更新请求,同样也是为了整个调谐方法逻辑处理的方便性。
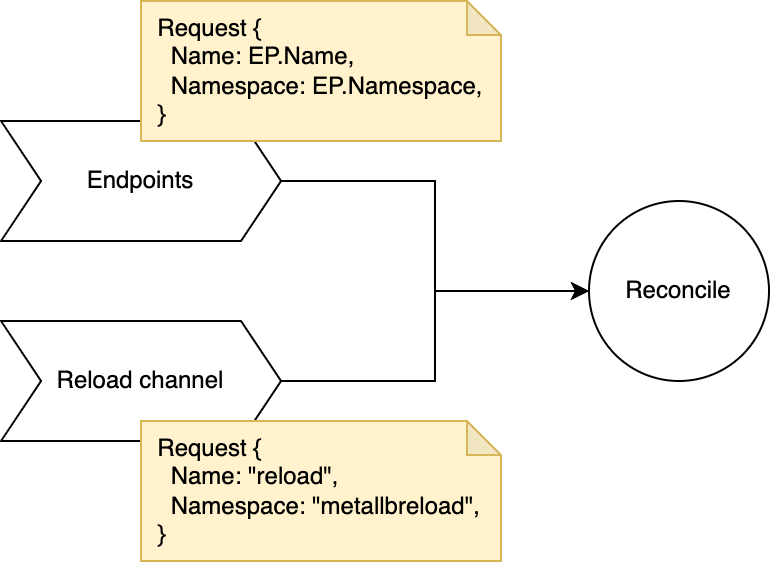
在 Service Controller 的实际调谐循环中,根据更新请求的类型来决定实际调谐的类型。另外,是否进行全量调谐,可通过ctrl.Request中特殊的NamespacedName值进行判断:
func (r *ServiceReconciler) Reconcile(ctx context.Context, req ctrl.Request) (ctrl.Result, error) {
if !isReloadReq(req) {
return r.reconcileService(ctx, req)
}
return r.reprocessAll(ctx, req)
}
// internal/k8s/controllers/service_controller_reload.go
func isReloadReq(req ctrl.Request) bool {
if req.Name == "reload" && req.Namespace == "metallbreload" {
return true
}
return false
}
全量调谐reprocessAll的实现其实就是把reconcileService调谐逻辑中对资源Get的方法替换为了List方法,但对于每个单独 Service 的处理逻辑不变。
SetBalancer
此方法就是在 Service Controller 的reconcileService调谐中使用的r.Handler方法,是用于处理 Service 类型资源发生更新时的方法。其大致流程为:
// controller/main.go
func (c *controller) SetBalancer(l log.Logger, name string, svcRo *v1.Service, _ epslices.EpsOrSlices) controllers.SyncState {
// 对于空的 Service 即触发回收 IP 操作
if svcRo == nil { // Read only
c.deleteBalancer(l, name) --->---
\
\
c.ips.Unassign(name)
// 触发后进行全量调谐,因为可能存在其他 LB 类型的 Service 在等待 IP 地址的分配
return controllers.SyncStateReprocessAll
}
// 在分配 IP 地址之前,先确保地址池是配置过的
if c.pools == nil || c.pools.ByName == nil {
return controllers.SyncStateSuccess
}
svc := svcRo.DeepCopy()
successRes := controllers.SyncStateSuccess
// 检查该服务是否被分配过 IP 地址
wasAllocated := c.isServiceAllocated(name) --->---
// 获取与分配 IP \
c.convergeBalancer(l, name, svc) \
c.ips.Pool(key) != ""
// convergeBalancer 可能会取消对 Service 的 IP 分配,若此种情况发生
if wasAllocated && !c.isServiceAllocated(name) {
// 被回收的 IP 地址可能还会被其他 LB 类型的 Service 使用,所以再进行全量调谐
successRes = controllers.SyncStateReprocessAll
}
// 对于没有发生任何变化的 Service,则直接返回
if reflect.DeepEqual(svcRo, svc) {
return successRes
}
toWrite := svcRo.DeepCopy()
// 最后再次与 svcRo 的 Status 字段进行比对,发生变化了则直接进行更新;因为 svc 在 convergeBalancer 中可能会发生变化
if !reflect.DeepEqual(svcRo.Status, svc.Status) {
toWrite.Status = svc.Status
}
// Annotations 字段也是,发生变化了则直接进行更新
if !reflect.DeepEqual(svcRo.Annotations, svc.Annotations) {
toWrite.Annotations = svc.Annotations
}
// 只有上述两个字段发生了更新时,才会引发这两者的不同,进而才会进行更新
if !reflect.DeepEqual(toWrite, svcRo) {
if err := c.client.UpdateStatus(svc); err != nil {
return controllers.SyncStateError
}
return successRes
}
return successRes
}
可以发现,MetalLB 对 Service 资源发生的变动集中在其Status和Annotations字段,其中被分配的 IP 会被写入到 Service 的Status字段中,具体来说是status.loadBalancer.ingress.ip,这也正是 k8s 期望发生的行为。
convergeBalancer
该方法在SetBalancer中被调用,是 Service Controller 用于 IP 地址分配的核心方法,也是整个 MetalLB 地址分配过程的核心方法。其所涉及的 IP 分配过程如下,由于方法过长,分段进行说明:
// controller/service.go
// #1
func (c *controller) convergeBalancer(l log.Logger, key string, svc *v1.Service) {
lbIPs := []net.IP{}
var err error
// 对于非 LoadBalancer 类型的 Service,可提前返回;同时还清除了 Service 的状态信息
if svc.Spec.Type != v1.ServiceTypeLoadBalancer {
c.clearServiceState(key, svc) --->---
return \
} \
\
func (c *controller) clearServiceState(key string, svc *v1.Service) {
c.ips.Unassign(key)
delete(svc.Annotations, annotationIPAllocateFromPool) // => "metallb.universe.tf/ip-allocated-from-pool"
svc.Status.LoadBalancer = v1.LoadBalancerStatus{}
}
// MetalLB 会根据 ClusterIP 的类型来决定使用的地址族,故对于没有 ClusterIP 的 Service 则直接返回
if len(svc.Spec.ClusterIPs) == 0 && svc.Spec.ClusterIP == "" {
c.clearServiceState(key, svc)
return
}
// ...
从上述过程来看,可以很好的诠释:为什么不在SetBalancer中就把 LoadBalancer 类型的 Service 筛选出来然后直接对它们进行 IP 分配?因为如果这样做的话,是只考虑了分配过程,而没有考虑回收。若直接对 LoadBalancer 类型的 Service 操作,则对于原来是 LoadBalancer 类型而现在是其他非 LoadBalancer 类型的 Service,它已被分配的 LB IP 就不能被回收,造成地址的无效占用。所以在此方法中进行筛选,并同时清除非 LoadBalancer 类型 Service 的 LB IP,以做到地址的回收。
另外,可以发现 MetalLB 对于 LoadBalancer 类型的 Headless Service 而言是无效的,这一点是合理的。因为对于没有 ClusterIP 的 Service 来说,LoadBalancer 类型是没有意义的,负载均衡器不会将流量转发到任何 Service 所代理的 Pods 上。对于这种情况,倒是可以使用 Ingress Gateway 将每个 Pod 对应到一个 Endpoint 上,从而对外公开服务。
// #2
// 获取所有在 Status 中 Ingress 字段出现的 IP 地址
for i := range svc.Status.LoadBalancer.Ingress {
ip := svc.Status.LoadBalancer.Ingress[i].IP
if len(ip) != 0 {
lbIPs = append(lbIPs, net.ParseIP(ip))
}
}
// 若 IP 地址为空,或是所有 IP 地址的解析都不正确,则会清除当前 Service 的状态
if len(lbIPs) == 0 {
c.clearServiceState(key, svc)
} else {
// 确定当前 LB IP 的 IP 地址家族
lbIPsIPFamily, err := ipfamily.ForAddressesIPs(lbIPs)
// 确定 ClusterIP 的 IP 地址家族
clusterIPsIPFamily, err := ipfamily.ForService(svc)
if err != nil {
return
}
// 若 LB IP 和 ClsuterIP 的 IP 地址家族不一致,则非有效的 IP 地址
if lbIPsIPFamily != clusterIPsIPFamily || lbIPsIPFamily == ipfamily.Unknown {
c.clearServiceState(key, svc)
lbIPs = []net.IP{}
}
}
// ...
注意,MetalLB 在处理status.loadBalancer.ingress字段的 IP 地址时,并没有肯定该字段记录的所有 IP 地址都是有效的。即不排除任何程序或用户对该字段值做出修改的可能,MetalLB 会对这些 IP 地址重新过一遍解析,保证 IP 地址的合法性。之后也保证了 LB IP 与 ClusterIP 的 IP 地址家族是一致的情况下,这些 IP 才是生效的(生效但并非有效)。
这里获取两者 IP 地址家族的函数,本质上都调用的是 ForAddresses,即对于只有一个 IP 的地址,根据其是 ipv4 还是 ipv6 类型来确定地址家族;而对于有两个 IP 的地址,两者只有在 IP 类型都不同的情况下,才可以确定使用 dual stack,否则对于相同的地址类型则返回错误。这也说明了 MetalLB 最多只能给每个 LoadBalancer 类型的 Service 分配两个不同类型的 IP。
// #3
// 对于现有的 LB IP,它们可能随着配置的更该而不再适用,所以需要再次进行检查并提供再次分配 LB IP 的机会
if len(lbIPs) != 0 {
// 地址分配的操作是幂等的,详细说明见下节内容
if err = c.ips.Assign(key, svc, lbIPs, k8salloc.Ports(svc), k8salloc.SharingKey(svc), k8salloc.BackendKey(svc)); err != nil {
c.clearServiceState(key, svc)
lbIPs = []net.IP{}
}
// 对于地址池 annotation 被修改的情况,意味着需要使用一个新的地址池进行地址分配
desiredPool := svc.Annotations[annotationAddressPool] // => "metallb.universe.tf/address-pool"
if len(lbIPs) != 0 && desiredPool != "" && c.ips.Pool(key) != desiredPool {
c.clearServiceState(key, svc)
lbIPs = []net.IP{}
}
// 获取期望的 LB IP
desiredLbIPs, _, err := getDesiredLbIPs(svc)
if err != nil {
return
}
// 若存在期望的 LB IP,且当前 LB IP 与期望的 LB IP 不同,则清空现有状态
if len(desiredLbIPs) > 0 && !isEqualIPs(lbIPs, desiredLbIPs) {
c.clearServiceState(key, svc)
lbIPs = []net.IP{}
}
}
// ...
之前检查完 IP 地址的合法性,现在就需要根据配置来检查其有效性。这里涉及一个获取期望 LB IP 的函数:getDesiredLbIPs,该函数首先尝试解析 Service Annotations字段中metallb.universe.tf/loadBalancerIPs对应的值,该值是一个由,分割 IP 拼接成的字符串;若该字段为空,则尝试获取Service.Spec.LoadBalancerIP对应的单个地址作为期望 LB IP。
为什么会存在这么一个期望的 LB IP 呢?因为大多数情况下负载均衡器分配 IP 地址是一个随机的过程,而期望的 LB IP 则描述了用户希望该 Service 使用的 IP。这个 LB IP 在地址分配时,会直接指定给 Service,当然也是在 IP 合法且有效的前提下。另外,若用户指定了期望的 LB IP,则 spec 中 AutoAssign 是要关闭的。
// #4
// 到此为止,对于没有 LB IP 的 Service 才进行地址分配,详细说明见下节内容
if len(lbIPs) == 0 {
lbIPs, err = c.allocateIPs(key, svc)
if err != nil {
return
}
}
// IP 分配失败
if len(lbIPs) == 0 {
c.clearServiceState(key, svc)
return
}
// 检查该分配 IP 对应的地址池是否存在
pool := c.ips.Pool(key)
if pool == "" || c.pools == nil || c.pools.IsEmpty(pool) {
c.clearServiceState(key, svc)
return
}
// 最后,记录分配的 IP 到 Service 的 Status 和 Annotations 字段
lbIngressIPs := []v1.LoadBalancerIngress{}
for _, lbIP := range lbIPs {
lbIngressIPs = append(lbIngressIPs, v1.LoadBalancerIngress{IP: lbIP.String()})
}
svc.Status.LoadBalancer.Ingress = lbIngressIPs
if svc.Annotations == nil {
svc.Annotations = make(map[string]string)
}
svc.Annotations[annotationIPAllocateFromPool] = pool // => "metallb.universe.tf/ip-allocated-from-pool"
}
最后,对于没有 LB IP 的 Service 进行地址分配,并保存到 Service 的Status和Annotations字段。地址分配使用的是 Service Controller 的allocateIPs方法:该方法按照先指定期望的 LB IP,再从指定地址池中分配 IP,最后再从所有的相关地址池中分配 IP 的优先级顺序去处理。
// controller/service.go
func (c *controller) allocateIPs(key string, svc *v1.Service) ([]net.IP, error) {
// 确定 Service 所使用的 IP 地址类型,确定方式见上文
serviceIPFamily, err := ipfamily.ForService(svc)
if err != nil {
return nil, err
}
desiredLbIPs, desiredLbIPFamily, err := getDesiredLbIPs(svc)
if err != nil {
return nil, err
}
// 若用户指定了期望 LB IP,则先尝试分配这个 IP
if len(desiredLbIPs) > 0 {
if serviceIPFamily != desiredLbIPFamily {
return nil, // err
}
if err := c.ips.Assign(key, svc, desiredLbIPs, k8salloc.Ports(svc), k8salloc.SharingKey(svc), k8salloc.BackendKey(svc)); err != nil {
return nil, err
}
return desiredLbIPs, nil
}
// 否则,从地址池中分配一个 IP 地址
desiredPool := svc.Annotations[annotationAddressPool]
if desiredPool != "" {
ips, err := c.ips.AllocateFromPool(key, svc, serviceIPFamily, desiredPool, k8salloc.Ports(svc), k8salloc.SharingKey(svc), k8salloc.BackendKey(svc))
if err != nil {
return nil, err
}
return ips, nil
}
// 若地址池没有被指定,则从所有跟该 Service 相关的地址池中分配
return c.ips.Allocate(key, svc, serviceIPFamily, k8salloc.Ports(svc), k8salloc.SharingKey(svc), k8salloc.BackendKey(svc))
}
核心结构:Allocator
上文提到的,所有涉及 IP 地址分配与回收的操作,使用的实际上都是由 Allocator 提供的接口,比如Unassign、Assign、Allocate等方法。
Allocator 作为 Service Controller 的一个字段出现,它本身是一个记录了 IP 到 Service 各种信息映射关系的数据结构。
type controller struct {
client service
pools *config.Pools
ips *allocator.Allocator
}
// internal/allocator/allocator.go
type Allocator struct {
pools *config.Pools
allocated map[string]*alloc // svc -> alloc,记录已分配的 IP 信息
sharingKeyForIP map[string]*key // ip.String() -> assigned sharing key
portsInUse map[string]map[Port]string // ip.String() -> Port -> svc
servicesOnIP map[string]map[string]bool // ip.String() -> svc -> allocated?
poolIPsInUse map[string]map[string]int // poolName -> ip.String() -> number of users
}
type alloc struct {
pool string
ips []net.IP
ports []Port
key --->---
} \
\
type key struct {
sharing string
backend string
}
多租户地址池与 IP 生成
Allocate方法是针对分配地址时无指定地址池情况使用的,该情况的处理首先作用于IPAddressPool.spec.serviceAllocation字段。这个字段是为了实现地址池的多租户能力而引入的,其中涉及了地址池的优先级(值越低优先级越高)、作用命名空间、命名空间选择器和 Service 选择器等特性,用于指定地址池的生效范围。若在这些租户的地址池中分配地址失败,才会 fallover 到全局非租户的地址池中尝试分配。
// internal/allocator/allocator.go
func (a *Allocator) Allocate(svcKey string, svc *v1.Service, serviceIPFamily ipfamily.Family, ports []Port, sharingKey, backendKey string) ([]net.IP, error) {
// 对于已经被分配地址的 Service,这里再次尝试指定地址
if alloc := a.allocated[svcKey]; alloc != nil {
// 指定的还是原来已经分配的地址,这里的主要目的是对原地址的合法性再次进行校验;若校验通过,Allocator.allocated 字段虽然会更新,但是内容不变
if err := a.Assign(svcKey, svc, alloc.ips, ports, sharingKey, backendKey); err != nil {
return nil, err
}
return alloc.ips, nil
}
// 获取 serviceAllocation 中规定的,与当前 Service 各种原数据或命名空间相匹配的地址池,并按照地址池的优先级降序排序
pinnedPools := a.pinnedPoolsForService(svc)
for _, pool := range pinnedPools {
// 只要从一个地址池中分配 IP 成功,则直接返回该分配的 IP
if ips, err := a.AllocateFromPool(svcKey, svc, serviceIPFamily, pool.Name, ports, sharingKey, backendKey); err == nil {
return ips, nil
}
}
// 遍历所有地址池,过滤掉所有非租户的地址池或不会自动分配 IP 的地址池
for _, pool := range a.pools.ByName {
if !pool.AutoAssign || pool.ServiceAllocations != nil {
continue
}
if ips, err := a.AllocateFromPool(svcKey, svc, serviceIPFamily, pool.Name, ports, sharingKey, backendKey); err == nil {
return ips, nil
}
}
return nil, errors.New("no available IPs")
}
对于从指定地址池中获取 IP 的过程,MetalLB 会遍历地址池的每个 CIDR,直到每种 IP 类型都被分配了一个 IP 地址为止;最后,再将分配的 IP 指定给当前 Service。其中,从一个 CIDR 中分配 IP,是 getIPFromCIDR 方法完成的工作,该方法本质上是调用的 ipaddr 库函数,MetalLB 使用该库完成对 IP 地址分配的追踪。除此之外,在该方法中还跳过了使用 IP 地址共享和 buggy 网络的地址。
func (a *Allocator) AllocateFromPool(svcKey string, svc *v1.Service, serviceIPFamily ipfamily.Family, poolName string, ports []Port, sharingKey, backendKey string) ([]net.IP, error) {
if alloc := a.allocated[svcKey]; alloc != nil {
// ...
if err := a.Assign(svcKey, svc, alloc.ips, ports, sharingKey, backendKey); err != nil {
return nil, err
}
return alloc.ips, nil
}
// 获取该指定的地址池对象
pool := a.pools.ByName[poolName]
ips := []net.IP{}
// 根据 IP 地址家族决定分配的地址类型
ipfamilySel := make(map[ipfamily.Family]bool)
switch serviceIPFamily {
case ipfamily.DualStack:
ipfamilySel[ipfamily.IPv4], ipfamilySel[ipfamily.IPv6] = true, true
default:
ipfamilySel[serviceIPFamily] = true
}
for _, cidr := range pool.CIDR {
// 地址池的 CIDR 要在和目的 IP 地址类型相同时,才能被分配
cidrIPFamily := ipfamily.ForCIDR(cidr)
if _, ok := ipfamilySel[cidrIPFamily]; !ok {
continue
}
ip := a.getIPFromCIDR(cidr, pool.AvoidBuggyIPs, svcKey, ports, sharingKey, backendKey) // 获取 IP
if ip != nil {
ips = append(ips, ip)
delete(ipfamilySel, cidrIPFamily)
}
}
// 存在没有被分配的 IP 地址类型,说明地址池已耗尽
if len(ipfamilySel) > 0 {
return nil, // err
}
err := a.Assign(svcKey, svc, ips, ports, sharingKey, backendKey) // 将分配后的 IP 指定给 Service
if err != nil {
return nil, err
}
return ips, nil
}
对于分配完成的 IP,则要通过Assign方法指定给对应的 Service。该方法首先对地址池和 IP 的有效性进行检查(包括检查共享 IP 的可用性),然后调用assign方法更新Allocator结构体的各个字段内容,例如:a.allocated[svc] = alloc。
func (a *Allocator) Assign(svcKey string, svc *v1.Service, ips []net.IP, ports []Port, sharingKey, backendKey string) error {
// check ...
alloc := &alloc{
pool: pool.Name,
ips: ips,
ports: make([]Port, len(ports)),
key: *sk,
}
copy(alloc.ports, ports)
a.assign(svcKey, alloc)
return nil
}
与之同理,Unassign方法用来回收 IP,其主要的工作就是清理Allocator结构体的各个字段跟当前 Service 有关的内容,例如:delete(a.allocated, svc)。
IP 地址共享机制
在上文的一些逻辑分析中,忽略了 IP 地址共享这种情况。MetalLB 引入 IP 地址共享这个功能,主要有两个目的:
- 打破 K8s 不支持 LoadBalancer 类型的 Service 在同一端口运行多协议的限制
- 当实际 Service 数量比可用 IP 地址数多时,用于解决 IP 地址不够用的问题
至于第一点,对于一个 DNS 服务就很实用,因为 DNS 服务既要监听 TCP 也要监听 UDP。但由于 K8s 的限制,不可能创建一个这样的 LoadBalancer Service。但在 MetalLB 中,可以通过创建两个 sharing-key 和spec.loadBalancerIP相同的服务,每个服务都关联相同的 pod 来解决这个问题。

对于使用 IP 地址共享的两个 Service 也存在一些条件限制:
- 它们需要拥有相同的 sharing-key
Annotation - 它们不能对相同端口使用相同的协议
- 它们都使用
Cluster模式的 External TrafficPolicy,或它们所代理的 pods 一样
// internal/allocator/allocator.go
func (a *Allocator) checkSharing(svc string, ip string, ports []Port, sk *key) error {
if existingSK := a.sharingKeyForIP[ip]; existingSK != nil {
// 检查 sharing-key 是否相同
if err := sharingOK(existingSK, sk); err != nil {
// ...
}
// 检查端口是否被占用,端口由协议和端口号两部分组成
for _, port := range ports {
if curSvc, ok := a.portsInUse[ip][port]; ok && curSvc != svc {
return // err
}
}
}
return nil
}
外部广播
待 MetalLB 给 Service 分配了一个 IP(External IP)之后,它还需要让外部集群的网络感知到这个 IP 的存在,即需要为 IP 对外进行广播。MetalLB 使用了标准路由协议(ARP、NDP 和 BGP)来实现这点,对此其拥有两种工作模式。
这两种工作模式在默认情况下是同时启用的,每种工作模式都有其对应的 controller 实现。
// speaker/main.go
func newController(cfg controllerConfig) (*controller, error) {
handlers := map[config.Proto]Protocol{
config.BGP: &bgpController{/*...*/},
}
protocols := []config.Proto{config.BGP}
if !cfg.DisableLayer2 { // 虽然有 Layer2 模式的开关,但在实现中并没有发现该配置的可设置项
a, err := layer2.New(cfg.Logger) // 初始化 Layer2 Announcer
handlers[config.Layer2] = &layer2Controller{/*...*/}
protocols = append(protocols, config.Layer2)
}
ret := &controller{ // 初始化 speaker 的 controller
// ...
protocolHandlers: handlers,
announced: map[config.Proto]map[string]bool{},
svcIPs: map[string][]net.IP{},
protocols: protocols,
}
ret.announced[config.BGP] = map[string]bool{}
ret.announced[config.Layer2] = map[string]bool{}
return ret, nil
}
这些 controller 都实现了Protocol接口,即满足了对外宣告 External IP 的基本方法。
type Protocol interface {
SetConfig(log.Logger, *config.Config) error
ShouldAnnounce(log.Logger, string, []net.IP, *config.Pool, *v1.Service, epslices.EpsOrSlices) string
SetBalancer(log.Logger, string, []net.IP, *config.Pool, service, *v1.Service) error
DeleteBalancer(log.Logger, string, string) error
SetNode(log.Logger, *v1.Node) error
}
在 speaker 中,任何与 Service 资源更新相关的事件都会被 Speaker 的 Controller 捕获,并调用每种工作模式进行处理。在handleService方法中,每种工作模式会先使用ShouldAnnounce来检查当前 Node 是否可以被用来做宣告工作;之后再使用SetBalancer来进行 IP 宣告。
for _, protocol := range c.protocols {
if st := c.handleService(l, name, lbIPs, svc, pool, eps, protocol); st == controllers.SyncStateError {
return st
}
}
Layer2 模式
在 L2 模式中,由一个 Node 上的 speaker 组件(DaemonSet)负责宣告 Service 在一个子网中的 External IP 地址(leader speaker),即该 IP 地址会出现在其 Node 的网络接口上,作为外界访问服务的流量入口。所有对 Service External IP 的流量都会被路由到一个 Node 上,当流量进入 Node 后,kube-proxy 会负责将流量分发到 Service 代理的不同 Pod 上。因为所有流量都只通过一个 Node 进入,所以严格意义上讲,MetalLB 并没有在 L2 模式中实现负载均衡器。相反,而是实现了一套故障转移或高可用机制,即当一个 speaker 不可用时,会有其他 Node 上的 speaker 接管宣告 Service External IP 的工作。
由于一个集群中可能会出现多个地址池,即多个子网,故针对每个子网,都会实施故障转移机制。如下图所示,Node A 和 B 属于同一个子网 A,那么 Node A 和 B 其中一个会被选为子网 A 的 leader speaker;而对于 Node C 来说,由于只有一个 Node 属于子网 B,故 Node C 会一直作为该子网的 leader speaker。
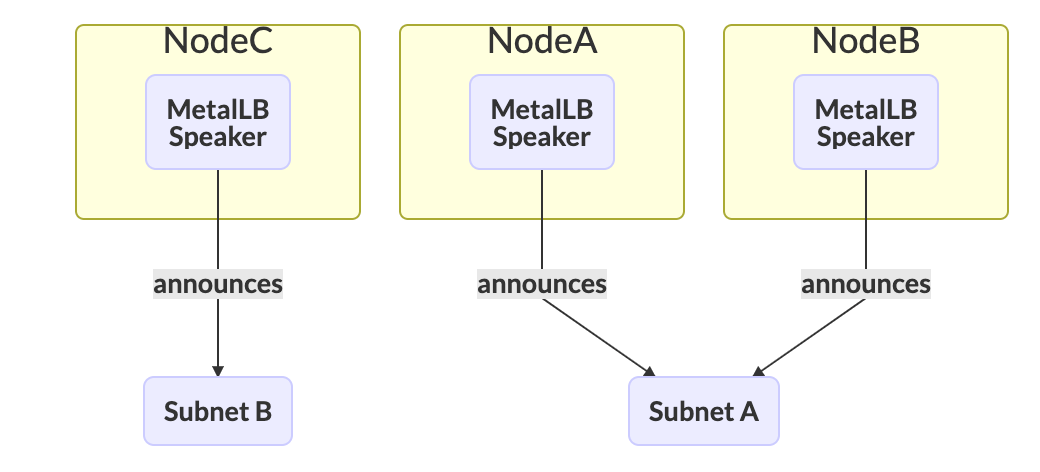
在路由协议的选择上,对于一个 ipv4 类型的 Service,speaker 会通过 ARP 请求来宣告 IP 地址;对于一个 ipv6 类型的 Service,speaker 则会通过 NDP 请求。值得注意的是,由于 L2 模式依赖 ARP 和 NDP 协议,所以必须保证请求客户端所在的网络与 Service External IP 属于同一个子网。
除此之外,当流量进入到 Node 时,kube-proxy 还会根据 Service 设置的不同ExternalTrafficPolicy来转发外部流量:
- 若为策略
cluster(默认),kube-proxy 会把流量转发到集群中该服务代理的所有不同 Pod 上。由于 kube-proxy 会对请求进行源地址伪装,所以在最终接收到这些外部流量时,它们的源地址都为 leader speaker 所在 Node 的 IP - 若为策略
local,kube-proxy 只会把流量转发到在当前 Node 上的 Service Pod,虽然这些 Pod 接受到流量的源地址是外部地址,但只会命中少部分 Pod,容易造成流量失衡
Leader 选举
在选举的过程中,leader speaker 候选者的产生存在以下几点前提要求:
- leader speaker 候选者必须要在被子网选中的 Node 上,Node 的挑选可通过 NodeSelector 进行,若不指定 Selector 则默认使用所有 Node
- Service 代理的所有 Pod 必须处于 Ready 状态
在 L2 模式下的完整 leader 选举流程,由ShouldAnnounce方法实现,该方法只要返回非空字符串,就说明此 speaker 不适合做 leader。
// speaker/layer2_controller.go
func (c *layer2Controller) ShouldAnnounce(l log.Logger, name string, toAnnounce []net.IP, pool *config.Pool, svc *v1.Service, eps epslices.EpsOrSlices) string {
// 检查 Endpoint 或 EndpointSlice 是否处于 Ready 状态
if !activeEndpointExists(eps) {
return "notOwner"
}
// 检查 speaker 所在 Node 是否匹配地址池中 L2Advertisements 的 NodeSelector
if !poolMatchesNodeL2(pool, c.myNode) {
return "notOwner"
}
// 选出所有匹配地址池中 L2Advertisements NodeSelector 的 speaker Node
forPool := speakersForPool(c.sList.UsableSpeakers(), pool) // 当然是从所有有效的 speaker 中选
var nodes []string
// 根据不同的外部流量策略,选出候选 Node
if svc.Spec.ExternalTrafficPolicy == v1.ServiceExternalTrafficPolicyTypeLocal {
// 对于 local 类型,只有 Endpoints 出现在的 Node 才可作为候选
nodes = usableNodes(eps, forPool)
} else {
// 对于 cluster 类型,上述所有 Node 都可作为候选
nodes = nodesWithActiveSpeakers(forPool)
}
ipString := toAnnounce[0].String()
// 根据 node 名 + LB IP 的哈希值对 nodes 进行排序
sort.Slice(nodes, func(i, j int) bool {
hi := sha256.Sum256([]byte(nodes[i] + "#" + ipString))
hj := sha256.Sum256([]byte(nodes[j] + "#" + ipString))
return bytes.Compare(hi[:], hj[:]) < 0
})
// 若当前 speaker Node 是排序后 Node 列表中的第一个,则就该由本 speaker 来承担宣告工作
if len(nodes) > 0 && nodes[0] == c.myNode {
return ""
}
return "notOwner"
}
leader speaker 候选者的产生还跟ExternalTrafficPolicy有关,如下图所示。对于 local 类型的外部流量策略来说,其只选择了 Service Pod 所在的 Node,因为若 leader speaker 选在了一个没有 Service Pod 的 Node 上,当外部流量进入该 Node 时,不会有任何的 Pod 来响应流量。
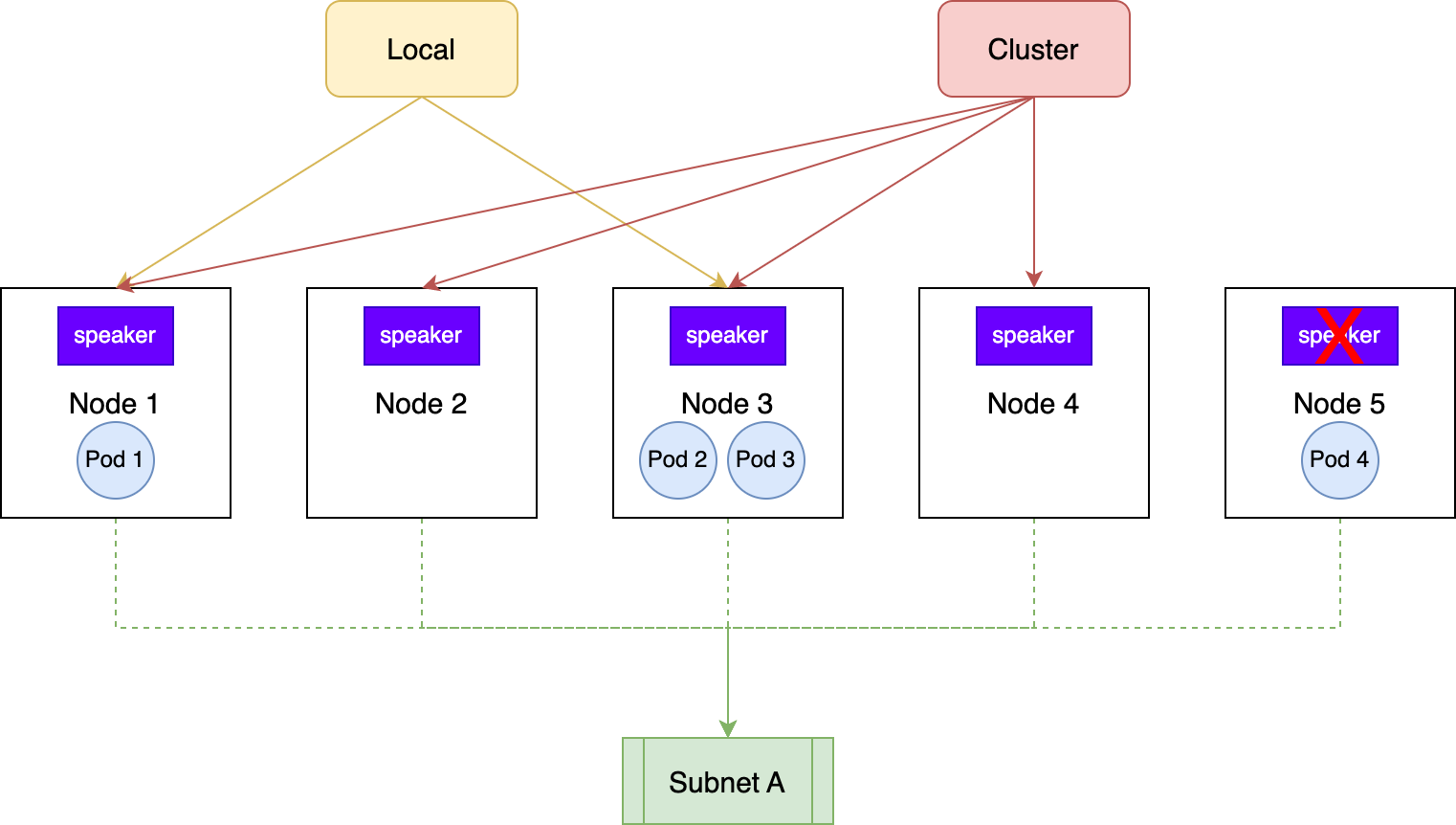
在选举 leader speaker 时,还对所有 Node 进行了一个排序。排序时只考虑了 Node Name 和 LB IP 两个因素,这种考虑对于共享的 IP 地址来说也管用,因为对于拥有相同 IP 的不同 Services 来说,它们的排序结果是唯一的。由于ShouldAnnounce方法被所有 speaker 执行,而且最终只选取当前 Node 与排序后第一个 Node 相同的 speaker,故最终选举的 leader speaker 只会存在一个。
Announcer 与接口
L2 controller 在初始化前,还初始化了 Announcer,该结构专门用于通告能映射当前节点 MAC 地址的新 IP,同时还启动了两个 goroutine 定时任务:interfaceScan用于定时扫描(固定每 10s 一次) Node 上的可用接口;spamLoop用于定时主动发送 ARP/NDP 响应(也监听spamCh通道)。
接口可用性判定的主要规则如下,其主要是确定接口是否启动、Linux 文件中是否存在该网络接口的符号链接,以及接口是否支持广播、是否开启 ARP 协议来解析目的 IP 的 MAC 地址。对于每一个可用的接口,speaker 都会根据其地址类型创建一个对应的 ARP/NDP Responder 实例,用于完成接口对各协议的请求与响应。
// internal/layer2/announcer.go
func (a *Announce) updateInterfaces() {
ifs, err := net.Interfaces()
// ...
for _, intf := range ifs {
ifi := intf
if ifi.Flags&net.FlagUp == 0 { // 是否启动
continue
}
if _, err = os.Stat("/sys/class/net/" + ifi.Name + "/master"); !os.IsNotExist(err) { // 是否存在
continue
}
f, err := os.ReadFile("/sys/class/net/" + ifi.Name + "/flags") // 是否支持 ARP
if err == nil {
flags, _ := strconv.ParseUint(string(f)[:len(string(f))-1], 0, 32)
// NOARP flag
if flags&0x80 != 0 {
continue
}
}
if ifi.Flags&net.FlagBroadcast != 0 { // 是否支持广播
keepARP[ifi.Index] = true
}
// ...
//初始化并保存所有接口对应的 Responder
if keepARP[ifi.Index] && a.arps[ifi.Index] == nil {
resp, err := newARPResponder(a.logger, &ifi, a.shouldAnnounce)
a.arps[ifi.Index] = resp
}
if keepNDP[ifi.Index] && a.ndps[ifi.Index] == nil {
resp, err := newNDPResponder(a.logger, &ifi, a.shouldAnnounce)
a.ndps[ifi.Index] = resp
}
}
// ...
}
在进行对外广播时,L2 controller 会将 Announcer 统计的 Node 上的所有接口与L2Advertisement CR 中规定使用的接口进行比较,只要有一个规定的接口属于所有接口,就会使用规定的接口进行对外广播。最终为 Service 的每个 LB IP 都可以生成一个IPAdvertisement的结构,其记录了与当前 IP 相关的接口集合。
// speaker/layer2_controller.go
func (c *layer2Controller) SetBalancer(l log.Logger, name string, lbIPs []net.IP, pool *config.Pool, client service, svc *v1.Service) error {
// 获取 Announcer 统计的接口
ifs := c.announcer.GetInterfaces()
for _, lbIP := range lbIPs {
// 获取该 LB IP 对应的 IPAdvertisement,里面记录了规定使用的接口
ipAdv := ipAdvertisementFor(lbIP, c.myNode, pool.L2Advertisements)
// 对比看两者接口是否匹配
if !ipAdv.MatchInterfaces(ifs...) {
continue
}
c.announcer.SetBalancer(name, ipAdv) // 对外进行广播
}
return nil
}
func ipAdvertisementFor(ip net.IP, localNode string, l2Advertisements []*config.L2Advertisement) layer2.IPAdvertisement {
ifs := sets.Set[string]{} // 记录规定使用的接口
for _, l2 := range l2Advertisements {
// 跳过不属于该 Node 的地址池
if matchNode := l2.Nodes[localNode]; !matchNode {
continue
}
// 若要使用所有接口,不设置任何配置即可
if l2.AllInterfaces {
return layer2.NewIPAdvertisement(ip, true, sets.Set[string]{})
}
ifs = ifs.Insert(l2.Interfaces...)
}
return layer2.NewIPAdvertisement(ip, false, ifs)
}
上文提及的“指定接口用于广播”是 MetalLB 在 #277 中提出,并由 #1536 引入的,用于支持 LB IP 只通过部分指定网络接口广播,而非全部可用接口。
引入这个机制的目的,在 Issue 中有很多讨论,其中个人认为最重要的一点就是:在 K8s 集群中监听一个 Node 上的所有接口,会产生许多没有意义的日志,这些接口也包括 CNI 为每个 Pod 创建的 veth pair。但从 MetalLB 实现来看,监听所有接口属于最简单的实现,因为 MetalLB 无法感知哪个接口对现在或以后都是否有用,这部分信息可能属于用户的先验。最终此机制通过 ConfigMap 暴露为可选配置项,但在提案的描述中,还提到了一个监听复杂类型多接口所引发的问题,如下图所示:
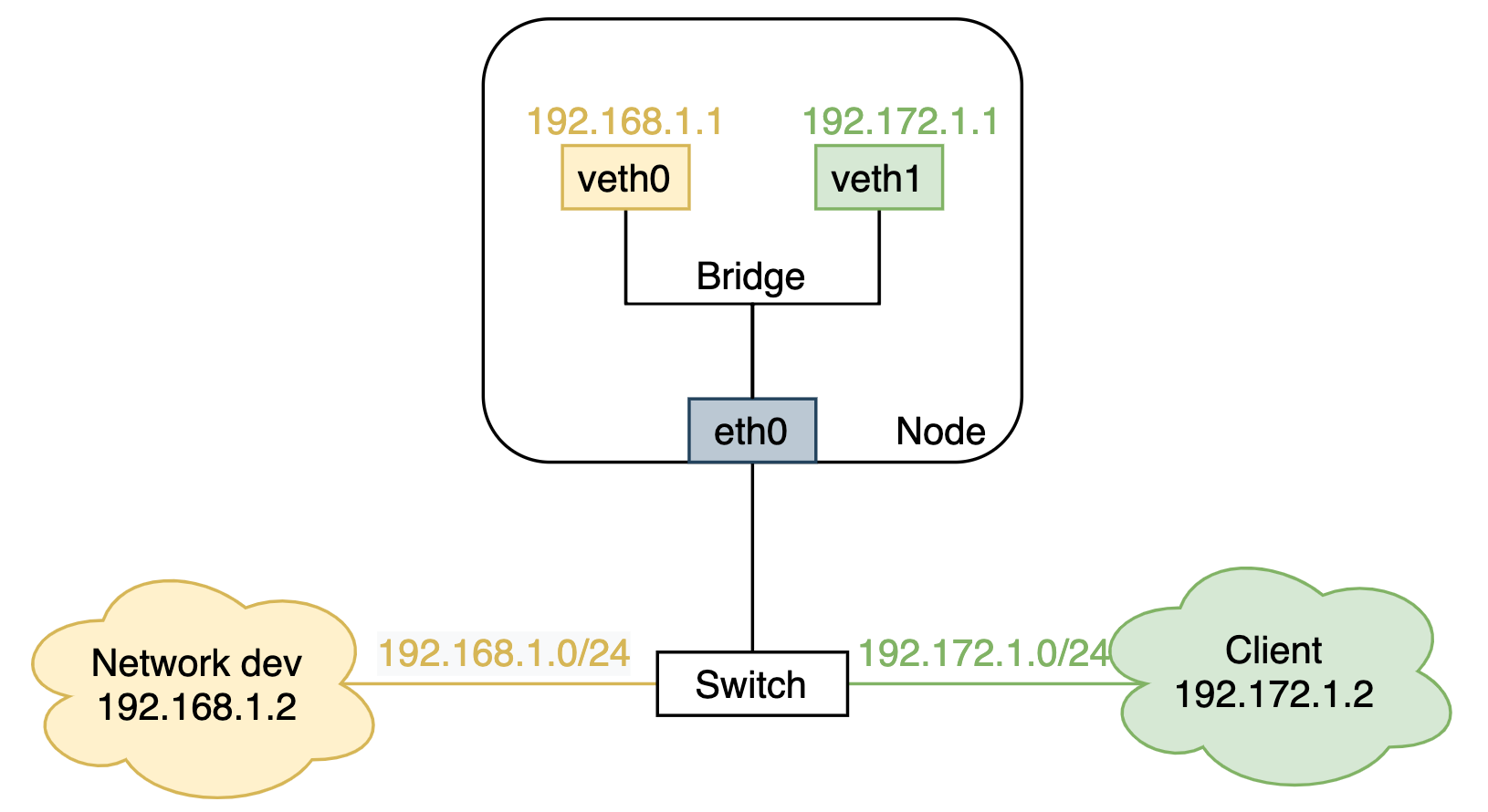
这个问题的大致意思是:对于所有复杂类型的接口(比如 bridge、ovs、macvlan 等),MetalLB 会从它们中接收所有 ARP 请求,并响应它们接口上所有从接口的 MAC 地址。
假设有两个虚拟接口 veth0 和 veth1 分别属于不同的子网,但都是 eth0 的从接口。若 MetalLB 在
192.172.1.0/24子网工作,并且给 LoadBalancer 类型的 Service 分配了该子网的 IP 地址(假设为192.172.1.10)。当客户端试图通过 IP 访问 Service 时,收到请求的可能不是 veth1 而是 veth0,因为 speaker 从所有接口广播了这个 VIP。
本文不会对该问题进行展开分析,因为这个问题就是作为提案的动机出现的,而且我也没有在 Issue 中找到类似在实际场景中的事故,所以很难展开。
Responder
每个接口 Responder 的对外广播都通过 Announcer 的SetBalancer方法触发,该方法最后会通过spamLoop进行一次 ARP/NDP 泛洪。
// internal/layer2/announcer.go
func (a *Announce) SetBalancer(name string, adv IPAdvertisement) { // name 为 Service name
// 向 spamCh 写入数据,触发 spamLoop 发送 ARP 响应
defer a.doSpam(adv) --->--- a.spamCh <- adv
a.Lock()
defer a.Unlock()
// 一个 Service 的 ipAdvertisement 可能会更新很多次,但只处理第一次
if ipAdvertisements, ok := a.ips[name]; ok {
for i := range ipAdvertisements {
if adv.ip.Equal(a.ips[name][i].ip) {
a.ips[name][i] = adv // 对于已有的,覆盖原来的值,以防接口变化了
return
}
}
}
a.ips[name] = append(a.ips[name], adv)
// 记录该 IP 的引用次数
a.ipRefcnt[adv.ip.String()]++
// ... 执行 defer
}
该泛洪实质上调用gratuitous方法,通过使用所有规定接口对应 Responder 的Gratuitous方法来进行 ARP/NDP 泛洪。
func (a *Announce) gratuitous(adv IPAdvertisement) {
a.RLock()
defer a.RUnlock()
ip := adv.ip
// 若当前 Node 对于 ip 的引用计数为 0,说明该 Node 不是进行广播的
if a.ipRefcnt[ip.String()] <= 0 {
return
}
if ip.To4() != nil {
for _, client := range a.arps {
// 只使用与规定接口匹配的 responder 接口
if !adv.matchInterface(client.intf) {
continue
}
client.Gratuitous(ip)
}
} else {
// 至于 ipv6 类型,处理方式也同上
for _, client := range a.ndps {
if !adv.matchInterface(client.intf) {
continue
}
client.Gratuitous(ip)
}
}
}
G/ARP 协议
ARP 模式的 Responder(ARPResp)在初始化时就向接口建立了连接,并开启 goroutine 对连接上的数据包进行读取。当然,并非所有读取到的数据包都是可用的:
// internal/layer2/arp.go
func (a *arpResponder) processRequest() dropReason {
pkt, eth, err := a.conn.Read()
if err != nil {
return dropReasonError
}
// 忽略 ARP 响应
if pkt.Operation != arp.OperationRequest {
return dropReasonARPReply
}
// 忽略非广播型并且目的 MAC 地址为当前节点的 ARP 请求
if !bytes.Equal(eth.Destination, ethernet.Broadcast) && !bytes.Equal(eth.Destination, a.hardwareAddr) {
return dropReasonEthernetDestination
}
// 忽略 Announcer 规定忽略的 ARP 请求
reason := a.announce(pkt.TargetIP, a.intf)
if reason != dropReasonNone {
return reason
}
a.conn.Reply(pkt, a.hardwareAddr, pkt.TargetIP) // 对 ARP 请求进行响应
return dropReasonNone
}
ARPResp 在过滤 ARP 请求时,还通过执行announce方法完成了 Announcer 规定的几种过滤规则,其中announce是 ARPResp 结构体的函数指针,它在 Announcer 初始化 ARPResp 时由 Announcer 的方法shouldAnnounce传入。该方法丢弃了目的 IP 地址非IPAdvertisements内的报文,而且还忽略了当前接口非有效(响应)接口时接受到的报文。
// internal/layer2/announcer.go
func (a *Announce) shouldAnnounce(ip net.IP, intf string) dropReason {
a.RLock()
defer a.RUnlock()
ipFound := false
for _, ipAdvertisements := range a.ips {
for _, i := range ipAdvertisements {
if i.ip.Equal(ip) {
ipFound = true
if i.matchInterface(intf) { // 是合法的 IP 但非规定的接口
return dropReasonNone
}
}
}
}
if ipFound {
return dropReasonNotMatchInterface
}
return dropReasonAnnounceIP
}
上述所描述的过程是 ARPResp 对外部一个 ARP 广播请求的响应,属于传统 ARP 的工作方式。但是对于 MetalLB 来说,每次 Service 的更新都可能引发 External IP 的变更,这些变更 IP 与 MAC 地址间的映射关系若不能被客户端或交换机及时的感知到(比如 ARP 缓存未及时更新),则会引发请求失败等问题,造成流量损失。
对此,MetalLB 采用了 ARP 的另外一种工作方式,即 Gratuitous ARP(GARP,暂译为无偿 ARP)。GARP 是一种 ARP 响应,只不过不是为响应 ARP 请求而生的,该响应本质上属于广播响应,一个典型的用处就是:用于宣告一个 host 在网络中的存在。在 GARP 的报文中,Opcode 被置为 2,表示报文类型为响应;源 MAC 和 IP 地址被置为报文发送者的地址,对应 MetalLB 中 speaker 的 IP 和 speaker 所在 Node 的 MAC 地址(具体来说是负责 IP 宣告的接口 MAC 地址);目的 MAC 地址被置为ffff.ffff.ffff(或0000.0000.0000取决于各 ARP 的实现),表示广播报文;目的 IP 地址还是发送者的 IP 地址,用于再次确认为哪个 IP 建立 ARP 映射。
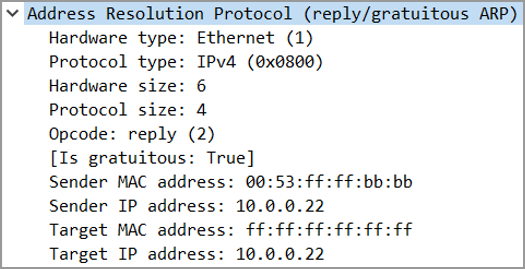
回看 ARPResp 在泛洪时对 GARP 的实现,可以发现其不仅发送了一个广播响应,还在此之前发送了一个报文内容一模一样的广播请求。关于为什么要引入一次广播请求报文?
- 历史原因。在早期的一些系统实现中,GARP 是以请求的方式广播的,如果只使用响应方式,那么对于一些旧系统来说,不会生效
- 另外,使用请求方式也存在一个好处,就是一旦 GARP 请求被回复了,说明在本网段内存在第二个跟当前 IP 相同的设备,证明 IP 地址冲突了;但在 MetalLB 中并没有对这点进行处理,因为在 MetalLB 中基本上不会出现地址冲突问题
// internal/layer2/arp.go
func (a *arpResponder) Gratuitous(ip net.IP) error {
for _, op := range []arp.Operation{arp.OperationRequest, arp.OperationReply} {
pkt, err := arp.NewPacket(op, a.hardwareAddr, ip, ethernet.Broadcast, ip)
a.conn.WriteTo(pkt, ethernet.Broadcast)
}
return nil
}
NDP 协议
由于 ipv6 没有 ARP,所以使用 NDP(Neighbor Discovery Protocol)协议完成 IP 地址到 MAC 地址的映射。对于 NDP 来说,其有 5 种消息类型,均使用 ICMPv6 做封装。
NDP 模式 Responder(NDPResp)的泛洪实现非常简单,其就是直接发送一个 Neighbor Advertisement(NA)类型的消息(ICMPv6 type 136)。但是注意,NA 类型的消息是通过一个特殊的 ipv6 多播地址ff02::1在链路本地范围内广播数据包的,即可以接受到该广播数据包的 Node 都应该加入到这个多播组中去。
// internal/layer2/ndp.go
func (n *ndpResponder) Gratuitous(ip net.IP) error {
err := n.advertise(net.IPv6linklocalallnodes, ip, true) // 特殊的 ipv6 多播地址
return err
}
func (n *ndpResponder) advertise(dst, target net.IP, gratuitous bool) error {
m := &ndp.NeighborAdvertisement{
Solicited: !gratuitous,
Override: gratuitous, // Should clients replace existing cache entries
TargetAddress: target,
Options: []ndp.Option{
&ndp.LinkLayerAddress{
Direction: ndp.Target,
Addr: n.hardwareAddr,
},
},
}
return n.conn.WriteTo(m, nil, dst)
}
所以 NDPResp 还涉及到两个方法:Watch和Unwatch,分别被 Announcer 在SetBalancer和DeleteBalancer时调用,目的就是将对外宣告的接口加入到这个多播组中,或从该多播组中删除。
func (n *ndpResponder) Watch(ip net.IP) error {
// ...
group, err := ndp.SolicitedNodeMulticast(ip)
if n.solicitedNodeGroups[group.String()] == 0 {
n.conn.JoinGroup(group)
}
n.solicitedNodeGroups[group.String()]++
return nil
}
func (n *ndpResponder) Unwatch(ip net.IP) error {
// ...
group, err := ndp.SolicitedNodeMulticast(ip)
n.solicitedNodeGroups[group.String()]--
if n.solicitedNodeGroups[group.String()] == 0 {
n.conn.LeaveGroup(group)
}
return nil
}
与 ARPResp 一样,NDPResp 在初始化时也开启了对接口的监听,并且对请求的处理过程也大同小异。NDPResp 只接受 NS 类型的消息,在消息目的 IP 地址与接口的 IP 地址一致时,才会发送对应单播类型的 NA 消息响应。
func (n *ndpResponder) processRequest() dropReason {
msg, _, src, err := n.conn.ReadFrom()
if err != nil {
return dropReasonError
}
// 只处理 NS 类型的消息
ns, ok := msg.(*ndp.NeighborSolicitation)
if !ok {
return dropReasonMessageType
}
// 提取发送者的源 MAC 地址
var nsLLAddr net.HardwareAddr
for _, o := range ns.Options {
lla, ok := o.(*ndp.LinkLayerAddress)
if !ok {
continue
}
if lla.Direction != ndp.Source {
continue
}
nsLLAddr = lla.Addr
break
}
if nsLLAddr == nil {
return dropReasonNoSourceLL
}
// announce 方法与上文 ARP Responder 中的一样
reason := n.announce(ns.TargetAddress, n.intf)
if reason != dropReasonNone {
return reason
}
n.advertise(src, ns.TargetAddress, false) // 回复 NA 类型的消息,单播地址
// ...
return dropReasonNone
}
Failover 机制
Leader speaker 的故障转移过程是自动的,MetalLB 使用 memberlist 完成对故障 Node 的检测工作。有关 memberlist 的解析并非本文重点。
memberlist 基于 Gossip 协议广播。每个 speaker 都维护了一份成员列表 speakerlist,具体来说,由于在 MetalLB 中使用了 memberlist 的DefaultLANConfig模式,所以 memberlist 维护的是集群内 Node 的 hostname 列表。speakerlist 跟随 speaker 进程启动,并在后台开启了三个 goroutine 分别负责定时(每五分钟)更新 speaker pod 的 IP 列表、监听 memberlist 中的成员加入或离开事件并触发 speaker controller 的 reload(跟上文reconcileService中提到的向reloadChan写事件是一码事)、监听并定时(每一分钟)尝试将新成员的 IP 加入到 speaker pod IP 列表中。
// internal/speakerlist/speakerlist.go
func (sl *SpeakerList) Start(client *k8s.Client) {
sl.client = client
// 初始化 pod IP 列表,即在 metallb-system 命名空间下的 speaker pod 的 IP
iplist, err := sl.mlSpeakers()
sl.mlMux.Lock()
sl.mlSpeakerIPs = iplist
sl.mlMux.Unlock()
go sl.updateSpeakerIPs()
go sl.memberlistWatchEvents()
go sl.joinMembers()
}
在 Leader 选举过程中用到的UsableSpeakers方法,其实也就是使用了 memberlist 对外提供的接口,获取当前可用的 Node 列表。
func (sl *SpeakerList) UsableSpeakers() map[string]bool {
if sl.ml == nil {
return nil
}
activeNodes := map[string]bool{}
for _, n := range sl.ml.Members() { // memberlist method
activeNodes[n.Name] = true
}
return activeNodes
}
实际上,speaker 的整个 L2 模式都是建立在 Failover 机制上的。如下图所示,当原有 leader speaker 下线后,memberlist 会向每个 speaker 响应一个NodeLeave事件。每个 speaker 在接收到事件后,都会强制触发(forceReload)一次全量的 Service 调谐循环。在调谐循环中,就又回到了上述 Leader 选举部分的工作,所有 speaker 都会根据 Node 的 hostname 和 Service 的 LB IP 组成的哈希值进行排序,排序结果在所有 speaker 中都是一样的,但只有当前 Node 的 hostname 与排序结果第一个一致的 speaker 才能被选举为 leader。最后由新的 leader 向所有子网内的 host 发送 GARP 报文,进行 ARP 映射关系更新。
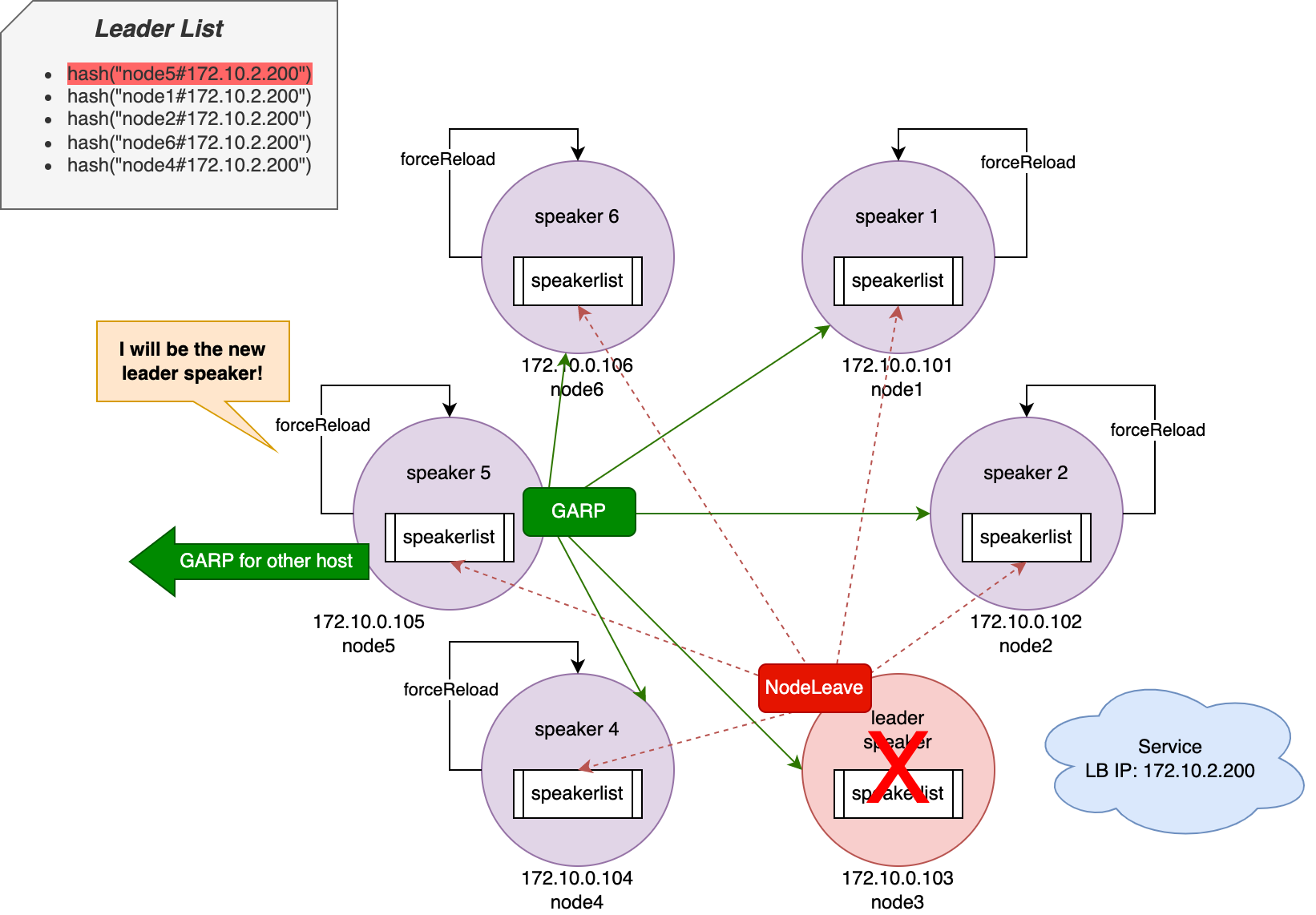
可见,在 L2 模式中,性能受限的原因只可能为两个:leader speaker 所在 Node 的带宽瓶颈,以及潜在的慢故障转移。针对后者来说,一次完整且成功的故障转移,需要经过 Leader 选举、广播 GARP、neighbor 更新 ARP 缓存这几个步骤,所以会在几秒内发生(官方指出一般不会超过 10s)。
BGP 模式
该模式下,所有 speaker 都会向每个(或指定的)BGP peer 去广播 Service 的 LB IP。这里所指的 BGP peer 是一类可以使用 BGP 协议的网络路由器,这些路由器包括真实的专业网络路由器,或其他任何运行了路由软件(比如 BIRD、Quagga 等)的设备。当路由器接受到请求 LB IP 的流量时,它会选出一个广播此 IP 的 speaker 所在的 Node,然后将流量转发到该 Node 上。进入到 Node 的流量会通过 kube-proxy 完成后续的转发工作,ExternalTrafficPolicy起到的效果与上文描述相同。
每当路由器接收到一次请求 LB IP 的新流量,它就会对一个 Node 建立一条新连接,具体选择哪个 Node 会因制造商或路由软件的实现而不同,但连接决策算法的目的就是实现流量的负载均衡,这也是 MetalLB 在 BGP 模式中体现负载均衡的地方。此时若有一个 Node 不可用了,路由器还会重新选择另一个 Node 并建立连接,这点也是 MetalLB 在 BGP 模式中对故障恢复机制的体现。

MetalLB 为 BGP 模式提供了两种实现类型:native和frr,由环境变量METALLB_BGP_TYPE指定,并在 speaker 创建 BGP controller 时初始化该类型对应的 session manager。
Native 实现
syncPeers
在 Node 与 Config 发生更新时,都会触发与 Router 即 BGP Peer 的状态同步。该动作发生于 BGP controller 的SetNode和SetConfig方法中:
- 由于 speaker 运行在每个 Node 上,故当 Node 发生创建、删除、更新(标签信息)时,都可能会引发与 BGP peer 的建立或回收连接
- BGP peer 可由
BGPPeerCRD 描述,故当 BGP peer 加入或移除集群时,都会引发与所有 speaker 的建立或回收连接
两个方法均负责捕获这种变化,最终它们都通过调用syncPeers方法进行状态同步。
// speaker/bgp_controller.go
func (c *bgpController) syncPeers(l log.Logger) error {
var (
errs int
needUpdateAds bool
)
// 遍历所有 peers,这些 peers 是当前最新的
for _, p := range c.peers {
// 匹配每个 peer 上的 NodeSeletor,决定该 Node 是否对当前 peer 生效
shouldRun := false
if len(p.cfg.NodeSelectors) == 0 {
shouldRun = true
}
for _, ns := range p.cfg.NodeSelectors {
if ns.Matches(c.nodeLabels) {
shouldRun = true
break
}
}
// 若 session 非空但是 Node 已经不生效了,则关闭当前 session
if p.session != nil && !shouldRun {
p.session.Close() // --->--- conn.Close()
p.session = nil
} else if p.session == nil && shouldRun {
// 若 session 不存在但是 Node 在生效中,则创建新的 session
var routerID net.IP
if p.cfg.RouterID != nil {
routerID = p.cfg.RouterID
}
s, err := c.sessionManager.NewSession(c.logger, // 创建 session 并尝试进行连接
bgp.SessionParameters{
// ...
},
)
p.session = s
needUpdateAds = true
}
}
// 对于有新创建 session 的情况,需要重新发送一次广播
if needUpdateAds {
err := c.updateAds()
}
return nil
}
这里 session 的创建是通过 session manager 的NewSession方法进行的,session manager 本质上是个接口。而 session 的关闭则会直接断开连接,值得注意的是,当一个 BGP session 终止后,它可能会影响其他活跃的连接(比如用户收到connection reset by peer等)。这虽然取决于各 Router 的实现,但也是 MetalLB 基于 BGP 协议做负载均衡不可回避的一个问题。如果用户在有先验的前提下,可以通过 NodeSelector 限制 BGP peer 与 Node 间的连接,以减少破坏范围。
// internal/bgp/bgp.go
type SessionManager interface {
NewSession(logger log.Logger, args SessionParameters) (Session, error)
SyncBFDProfiles(profiles map[string]*config.BFDProfile) error
}
此处调用NewSession方法创建的就是一个 Native 类型的 session。session 创建的同时,还启动了两个 goroutine,一个负责创建向 BGP peer 的连接,另一个负责在连接建立成功之后定时(通过BGPPeer.spec.holdTime配置)向 BGP peer 发送 KEEPALIVE 消息。值得注意的是,虽然 speaker 向 BGP peer 建立的是 TCP 连接,但 MetalLB 使用了一种相对底层的方式:通过 socket 完成。这样做的原因包括:
- 方便写入 TCP 的 MD5 签名,
BGPPeer.spec.password规定了在 BGP session 中使用 TCP MD5 认证// internal/bgp/native/native.go if password != "" { sig := buildTCPMD5Sig(raddr.IP, password) b := *(*[unsafe.Sizeof(sig)]byte)(unsafe.Pointer(&sig)) // fd 是与本地地址绑定的 socket,本地地址若在 BGPPeer.spec.sourceAddress 中没有指定,则使用 0:0:0:0(或 ipv6 的 [::]),表示所有可用地址 if err = os.NewSyscallError("setsockopt", unix.SetsockoptString(fd, unix.IPPROTO_TCP, tcpMD5SIG, string(b[:]))); err != nil { return nil, err } } - 可以基于 Epoll 完成对连接建立成功事件的轮询机制,并配合 Context 完成对连接建立的超时等待
fi := os.NewFile(uintptr(fd), "") epfd, err := unix.EpollCreate1(syscall.EPOLL_CLOEXEC) events := make([]unix.EpollEvent, 1) event.Events = syscall.EPOLLIN | syscall.EPOLLOUT | syscall.EPOLLPRI event.Fd = int32(fd) unix.EpollCtl(epfd, syscall.EPOLL_CTL_ADD, fd, &event) for { timeout := int(-1) if deadline, ok := ctx.Deadline(); ok { // timeout 处理 } nevents, err := unix.EpollWait(epfd, events, timeout) nerr, err := unix.GetsockoptInt(fd, unix.SOL_SOCKET, unix.SO_ERROR) // socket 状态处理,建立成功的话就返回:net.FileConn(fi) }
BGP 协议规定:当连接建立成功后,对端各自都要发送一个 OPEN 消息(bgp_hdr_type=1),若该消息成功被接受,则需要各自回复一个 KEEPALIVE 消息(bgp_hdr_type=4)。在 MetalLB 中,这些工作在连接建立成功后就立马进行了,并开启了一个 goroutine consumeBGP用于消费 BGP peer 发来的消息(只接受不回复)。至此,Node 与 BGP peer 间成功建立连接并开启 session。
updateAds
除了上述“在syncPeers结束时,若本次同步涉及新的 session 创建,则调用updateAds方法进行 LB IP 的广播”之外;每当 Service 资源发生变化时,也会使用此方法进行广播。
// speaker/bgp_controller.go
func (c *bgpController) updateAds() error {
var allAds []*bgp.Advertisement
for _, ads := range c.svcAds {
allAds = append(allAds, ads...)
}
for _, peer := range c.peers {
if peer.session == nil {
continue
}
// 针对已建立 session 的 peer 进行 IP 广播
if err := peer.session.Set(allAds...); err != nil {
return err
}
}
return nil
}
Service 的变化通过 speaker controller 的SetBalancer方法感知,之后会经由与 L2 模式一样的步骤:
bgpController.ShouldAnnounce根据 Node 是否在地址池中,以及ExternalTrafficPolicy的不同决定该 Node 是否进行广播bgpController.SetBalancer负责遍历 Service 的每个 LB IP,并为其创建bgp.Advertisement结构,该结构记录了一个 IP 的对端 peers 信息
updateAds方法会向所有已建立 session 的 peer 发送所有 LB IP 的广播,当然有许多 IP 根本不是当前 peer 负责的,这个也会在各自 peer 的 session 中进行过滤:
// internal/bgp/native/native.go
func (s *session) Set(advs ...*bgp.Advertisement) error {
s.mu.Lock()
defer s.mu.Unlock()
newAdvs := map[string]*bgp.Advertisement{}
for _, adv := range advs {
// 遍历该 IP 对应的所有 peers,看当前 peer 是否在其中,若在则匹配
if !adv.MatchesPeer(s.SessionName) {
continue
}
// 目前只能广播 ipv4 类型的 IP 地址
err := validate(adv)
if err != nil {
return err
}
newAdvs[adv.Prefix.String()] = adv
}
s.new = newAdvs
s.cond.Broadcast()
return nil
}
最后的条件变量cond.Broadcast()会通过sendUpdate或sendWithdraw触发 BGP 协议 UPDATE 消息(bgp_hdr_type=2)的发送,消息中含有要增加或删除的 LB IP 的路由。
FRR 实现
MetalLB 除了上述的 Native 方式实现,还支持 FRR 方式的实现。FRR 是个基于 Linux 的强大路由开源软件,它支持各种路由协议,MetalLB 就使用了其 BGP 协议的实现。如果启用 FRR 模式,BGP session 将支持 BFD、支持 ipv6,MetalLB 也会支持各种其他路由协议的实现(比如 RIP、OSPF 等)。
配合方式
在实现上,FRR 是作为一个额外的容器出现在 speaker 的 Pod 中。speaker 容器通过写配置文件的方式完成对 FRR 容器的控制,配置文件的内容是 frr session manager 根据 BGP 的配置来编写的(详见createConfig方法),生成的配置会写入 manager 的reloadConfig通道。通道的另一端是一个负责读取并将配置写入到文件的 goroutine。引发配置写入通道的时机有很多,包括:每次 session 的创建与关闭、以及 session 进行 IP 广播时。所以配置文件的 I/O 读写能力一定程度上成为了 FRR 模式的性能瓶颈,为避免此问题,MetalLB 和 Istio 类似,都采用了一种 debounce 机制:即对于一个新配置而言,不立马进行文件写入,而是等待 3s(不可配置),将此段时间内的所有配置“压缩为”一个请求写入到文件。
// internal/bgp/frr/config.go
func debouncer(body func(config *frrConfig) error, reload <-chan reloadEvent, reloadInterval time.Duration, failureRetryInterval time.Duration, l log.Logger) {
go func() {
var config *frrConfig
var timeOut <-chan time.Time
timerSet := false
for {
select {
case newCfg, ok := <-reload:
if !ok { // the channel was closed
return
}
if newCfg.useOld && config == nil { // useOld 字段由配置的定时验证方法进行设置,若配置出现任何问题,则该字段为 true
continue
}
if !newCfg.useOld && reflect.DeepEqual(newCfg.config, config) { // 忽略配置不变的请求
continue
}
if !newCfg.useOld {
config = newCfg.config // 压缩配置的方法很粗暴,就是直接使用该时间段内最新的配置
}
if !timerSet { // 设置等待时间
timeOut = time.After(reloadInterval)
timerSet = true
}
case <-timeOut:
err := body(config) // 写入 FRR 配置文件
if err != nil { // 若出现错误则进行重试
timeOut = time.After(failureRetryInterval) // 重试间隔 5s,不可配置
timerSet = true
continue
}
timerSet = false
}
}
}()
}
配置文件写入成功后,至此 BGP 的能力(包括负载均衡、故障转移等)就完全交付给了 FRR。有关 FRR 如何实现 BGP 并非本文关注点,感兴趣可参考此文档。
快速故障检测
开启 FRR 模式的另一个好处就是可以在 BGP session 中使用 BFD 协议。在 Native 实现中,holdTime规定了一个失败 session 所存活的时间,该时间越小,故障检测的速度就越快,但这个时间值规定最低为 3s,所以对于一些极其依赖快速检测的场景来说,时间还是太长了。而 BFD 协议提供了一种能双向快速检测故障的方法,可以将故障检测的时长降低至亚秒级。
MetalLB 使用了 FRR 提供的 BFD 实现,并提供了一个BFDProfile CR,用于暴露 BFD 的配置。当开启 FRR 方式后,bgp controller 除了会触发syncPeers进行状态同步,还会调用syncBFDProfiles方法将BFDProfile翻译为 FRR 配置文件:
// internal/bgp/frr/frr.go
func (sm *sessionManager) SyncBFDProfiles(profiles map[string]*metallbconfig.BFDProfile) error {
sm.Lock()
defer sm.Unlock()
sm.bfdProfiles = make([]BFDProfile, 0)
for _, p := range profiles {
frrProfile := configBFDProfileToFRR(p) // CR 翻译为 FRR 配置
sm.bfdProfiles = append(sm.bfdProfiles, *frrProfile)
}
sort.Slice(sm.bfdProfiles, func(i, j int) bool {
return sm.bfdProfiles[i].Name < sm.bfdProfiles[j].Name
})
frrConfig, err := sm.createConfig() // 根据当前 manager 的状态生成一份最新的配置文件
sm.reloadConfig <- reloadEvent{config: frrConfig} // 写入配置通道,之后完成写入配置
return nil
}
总结
MetalLB 的两个组件:controller 和 speaker,都是标准的 K8s controller 实现。其中 controller 组件负责地址分配,对 Service 资源进行 External IP 的分配和回收。个人认为地址池的多租户模式和IP 地址的共享机制是最能体现 MetalLB 地址管理灵活性的两个点,当然也不否认这对代码复杂度的影响。另外,从 controller 组件中 Allocator 的代码实现上来看,它基本上每个对外方法都是具备幂等性的,这对于需要频繁验证或更新数据的场景来说,是一个很鲁棒、很重要的性质。
外部广播由 speaker 组件负责,其兼顾了二层(ARP 和 NDP)及三层(BGP)协议。很有意思的是,MetalLB 作为一个负载均衡器并没直接实现负载均衡,在 L2 模式中通过故障恢复实现了 LB IP 的高可用,最终负载均衡能力还是由 kube-proxy 承担;在 L3 模式中则是通过 BGP 路由软件的实现来做负载均衡。所以与其说 MetalLB 是一个负载均衡器,不如说 MetalLB 只是充当了各协议间的“粘合剂”。
MetalLB 可直接部署在 K8s 裸机集群中。它最初由 Google 团队在 2017 年开发,于 2021 年成为 CNCF Sandbox 项目。MetalLB 正如本文解析的那样,本身并无神秘感;最值得探究的,反而是 MetalLB 所使用的这些网络协议,针对此点,本文浅尝辄止。
Reference
- https://metallb.universe.tf/
- https://github.com/metallb/metallb/blob/main/design/pool-configuration.md
- https://github.com/metallb/metallb/blob/main/design/layer2-bind-interfaces.md
- https://github.com/metallb/metallb/blob/main/design/0001-frr.md
- https://github.com/metallb/metallb/blob/main/design/bgp-bfd.md
- https://www.practicalnetworking.net/series/arp/gratuitous-arp/
- https://datatracker.ietf.org/doc/html/rfc5227#section-3
- https://datatracker.ietf.org/doc/html/rfc1654
- https://datatracker.ietf.org/doc/html/rfc5880
- https://en.wikipedia.org/wiki/Address_Resolution_Protocol#ARP_announcements
- http://linux-ip.net/html/ether-arp.html#ex-ether-arp-gratuitous
- https://www.networkacademy.io/ccna/ipv6/neighbor-discovery-protocol
- https://cloud.redhat.com/blog/metallb-in-bgp-mode
- https://access.redhat.com/documentation/en-us/openshift_container_platform/4.13/html/networking/load-balancing-with-metallb