本文同为:
- Greptime 官方微信公众号推文:GreptimeDB 的 KubeBlocks 集成经验分享
- Greptime Official Blogs: Hands-on Experience of Integrating GreptimeDB with KubeBlocks

KubeBlocks 是什么
KubeBlocks 是一款由 ApeCloud 开源的云原生数据基础设施,旨在帮助应用开发者和平台工程师在 Kubernetes 上更好地管理数据库和各种分析型工作负载。KubeBlocks 支持多个云服务商,并且提供了一套声明式、统一的方式来提升 DevOps 效率。
KubeBlocks 目前支持关系型数据库、NoSQL 数据库、向量数据库、时序数据库、图数据库以及流计算系统等多种数据基础设施。
KubeBlocks 的名字源自 Kubernetes(K8s)和乐高积木(Blocks),致力于让 K8s 上的数据基础设施管理就像搭建乐高积木一样,既高效又有趣。
为什么集成 KubeBlocks
现如今,构建数据基础设施在 K8s 上变得越来越流行。然而,这其中最棘手的障碍莫过于:与云提供商集成的困难、缺乏可靠的 Operators 以及陡峭的 K8s 学习曲线。
KubeBlocks 提供了一个开源选择,既可以帮助应用开发者和平台工程师为各种数据基础设施配置更多丰富的功能与服务,又可以帮助非 K8s 专业人士快速的搭建全栈、生产级的数据基础设施。
GreptimeDB 集成 KubeBlocks,不仅获得了更加方便、快捷的集群部署方式,而且还可以享受到 KubeBlocks 提供的扩缩容、监控、备份与恢复等强大的集群管理能力。何乐而不为?
KubeBlocks 集成思路
KubeBlocks 将一个集群(Cluster)所需的信息分成了三类:
- 拓扑信息,即 ClusterDefinition 资源对象,定义了集群所需组件及组件的部署方式等信息
- 版本信息,即 ClusterVersion 资源对象,定义了各组件镜像版本及相关配置信息
- 资源信息,即 Cluster 资源对象,定义了 CPU、内存、磁盘及副本数等资源信息
KubeBlocks 将一个集群中的拓扑、版本和资源解耦,使得每一个对象描述的信息都更加的清晰和聚焦,通过这些对象的组合可以生成更丰富的集群。 由上述三种对象描述的一个集群,其对象之间的组成关系如下图所示。
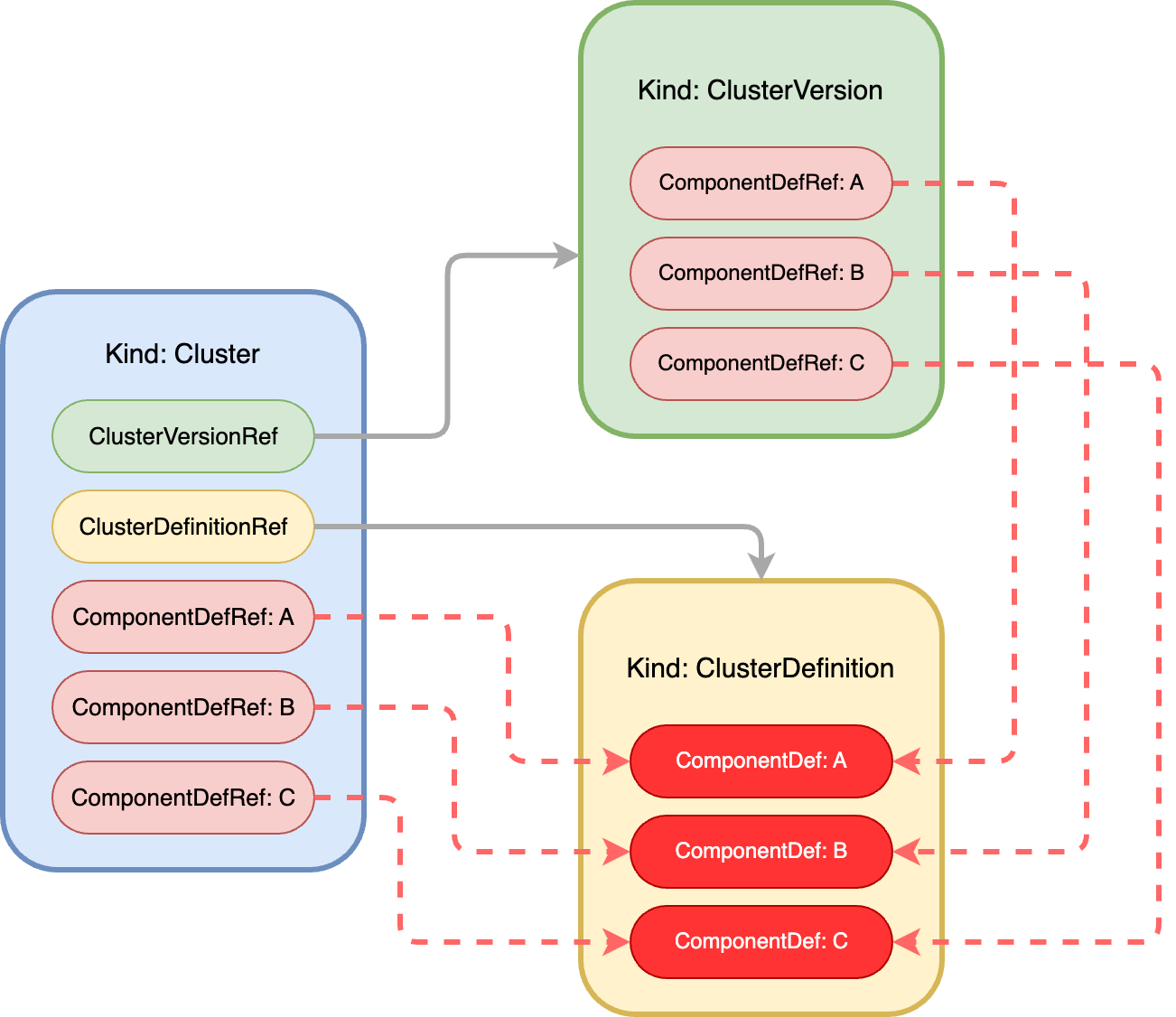
其中,ComponentDef 定义了一个集群中某个组件的部署信息,而 ComponentDefRef 描述了对某组件定义的一个引用。在此引用中,可以定义与对应组件相关的各种对象信息(比如在 ClusterVersion 的ComponentDefRef: A中定义组件 A 所使用的镜像版本为 latest;在 Cluster 的ComponentDefRef: A中定义组件 A 的副本数为 3 等等)。
综上所述,集成 KubeBlocks 实质上就是声明能够描述一个集群的拓扑、版本和资源的信息。
GreptimeDB 集群架构简介
GreptimeDB 集群的架构由三个组件组成:meta、frontend 和 datanode,如下图所示。
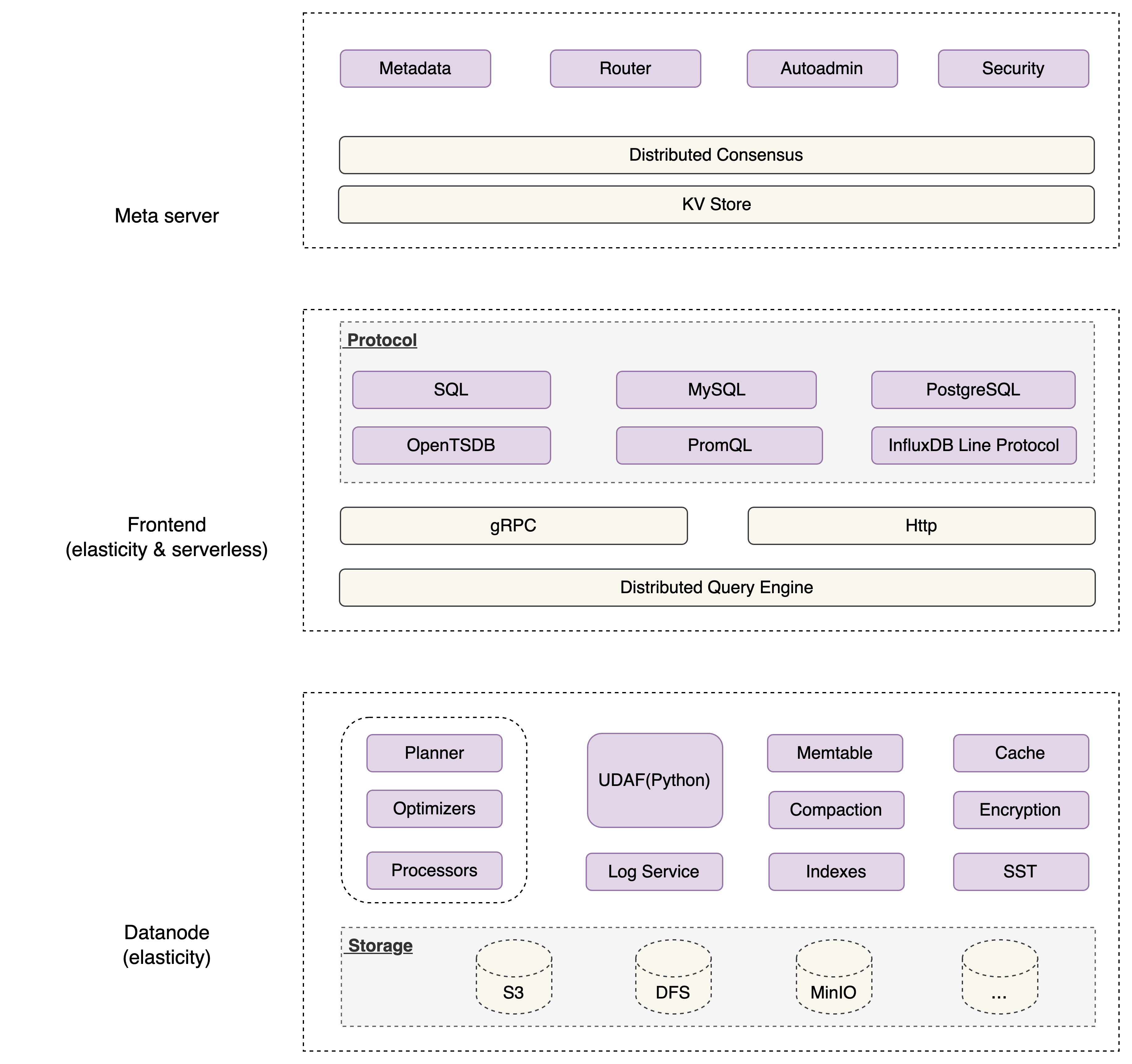
其中:
- frontend 负责暴露不同协议的读写接口,转发请求到 datanode;属于无状态类型组件
- datanode 负责数据的持久化存储;属于有状态类型组件
- meta 负责 frontend 与 datanode 间的协同;属于无状态类型组件;本文假设 meta 所使用的 kv-store 为 etcd
集成经验分享
有关完整的 GreptimeDB 对 KubeBlocks 的集成与运行方式,可以参考以下 PR:
本文不会对详细的配置信息展开赘述,而是分享几点在集成过程中的经验,希望对读者有所帮助。
跨组件的值引用
在一个集群中,有时会出现一个组件引用另一个组件中值的情况。比如在 GreptimeDB 集群中,frontend 组件引用了 meta 组件和 datanode 组件的 Service 地址。
KubeBlocks 提供了一个 componentDefRef 字段,允许跨组件值引用的发生。如下配置所示,frontend 组件声明了一个名为metaRef的引用,其引用了 meta 组件所创建 Service 的服务名,并且将该服务名保存在了GREPTIMEDB_META_SVC环境变量中,可供 frontend 组件或其他声明了该引用的组件使用。
componentDefs:
- name: frontend
componentDefRef:
- &metaRef
componentDefName: meta
componentRefEnv:
- name: GREPTIMEDB_META_SVC
valueFrom:
type: ServiceRef
# ...
containers:
- name: frontend
args:
- --metasrv-addr
- $(GREPTIMEDB_META_SVC).$(KB_NAMESPACE).svc:3002
# ...
- name: datanode
componentDefRef:
- *metaRef
podSpec:
containers:
- name: datanode
args:
- --metasrv-addr
- $(GREPTIMEDB_META_SVC).$(KB_NAMESPACE).svc:3002
# ...
不仅有对 Service 的引用,KubeBlocks 还支持对组件 Spec 中的字段(Field)或 Headless Service 的引用。
组件之间的启动顺序约束
一般一个集群会由多个组件组成,一个组件的启动可能依赖于另一个组件的状态。以 GreptimeDB 集群为例,其四个组件要依次按照 etcd、meta、datanode 和 frontend 的顺序启动。
KubeBlocks 在部署一个集群时,会同时启动所有组件。由于各组件的启动是无序的,若一个被依赖的组件在某个依赖它的组件启动之后运行,就会导致后者的启动失败,触发重启。比如 etcd 组件在 meta 组件启动之后才运行,就会导致 meta 组件的重启。若对各组件的启动顺序置之不理,虽然集群最后也能成功部署,但无疑增加了集群整体部署的时长;而且每个组件都会“平白无故”的增加重启计数,显然不够“优雅”。
考虑到 K8s 提供的 Init Container 功能,故在需要组件间启动顺序约束的场景下,可以引入initContainers来检测所依赖组件的状态。如下配置所示,配合componentDefRef功能,meta 会等待 etcd 的 Service 创建完成后再启动。
componentDefs:
- name: meta
componentDefRef:
- &etcdRef
componentDefName: etcd
componentRefEnv:
- name: GREPTIMEDB_ETCD_SVC
valueFrom:
type: ServiceRef
podSpec:
initContainers:
- name: wait-etcd
image: busybox:1.28
imagePullPolicy:
command:
- bin/sh
- -c
- |
until nslookup ${GREPTIMEDB_ETCD_SVC}-headless.${KB_NAMESPACE}.svc; do
echo "waiting for etcd"; sleep 2;
done;
# ...
灵活的 ConfigMap 挂载
在 ClusterDefinition 配置中,我们往往会“不自觉地”将 ConfigMap 在组件的 containers 中挂载:
apiVersion: v1
kind: ConfigMap
metadata:
name: greptimedb-meta
# ...
---
# ...
componentDefs:
- name: meta
podSpec:
containers:
- name: meta
volumeMounts:
- mountPath: /etc/greptimedb
name: meta-config
# ...
volumes:
- configMap:
name: greptimedb-meta
name: meta-config
这种挂载方式在当 Cluster、ClusterDefinition、ClusterVersion 对象位于同一个命名空间下时才生效,若它们位于不同命名空间下时,ConfigMap 的挂载就失效了。因为 ConfigMap 是一种 Namespaced 资源对象。
KubeBlocks 提供了一个 ConfigSpec 字段来解决上述问题。如下述配置所示,templateRef对应所引用的 ConfigMap 的名称。
apiVersion: v1
kind: ConfigMap
metadata:
name: greptimedb-meta
# ...
---
# ...
componentDefs:
- name: meta
configSpecs:
- name: greptimedb-meta
templateRef: greptimedb-meta
volumeName: meta-config
namespace:
podSpec:
containers:
- name: meta
volumeMounts:
- mountPath: /etc/greptimedb
name: meta-config
-
# ...
总结
本文分享了一些 GreptimeDB 集成 KubeBlocks 时的经验,这些都是在集成过程中碰到的真实问题与解决方法。
目前 GreptimeDB 只集成了 KubeBlocks 的部署能力,还有许多丰富的特性没有实施集成。争取在未来,将 GreptimeDB 集成更多 KubeBlocks 的能力。