Pod 自动垂直伸缩(Vertical Pod Autoscaler,VPA)是 K8s 中集群资源控制的重要一部分。它主要有两个目的:
- 通过自动化配置所需资源的方式来降低集群的维护成本
- 提升集群资源的利用率,减少集群中容器发生 OOM 或 CPU 饥饿的风险
本文以 VPA 为切入点,分析了 Autoscaler 和 Kubernetes In-Place 的 VPA 实现方式。
Autoscaler
此部分内容对应的代码基于 Autoscaler HEAD fbe25e1。
Autoscaler 的 VPA 会根据 Pod 的真实用量来自动的调整 Pod 所需的资源值,它通过引入 VerticalPodAutoscaler API 资源来实现,该资源定义了匹配哪些 Pod(label selector)使用何种更新策略(update policy)去更新以何种方式(resources policy)计算的资源值。
Autoscaler 的 VPA 由以下模块配合实现:
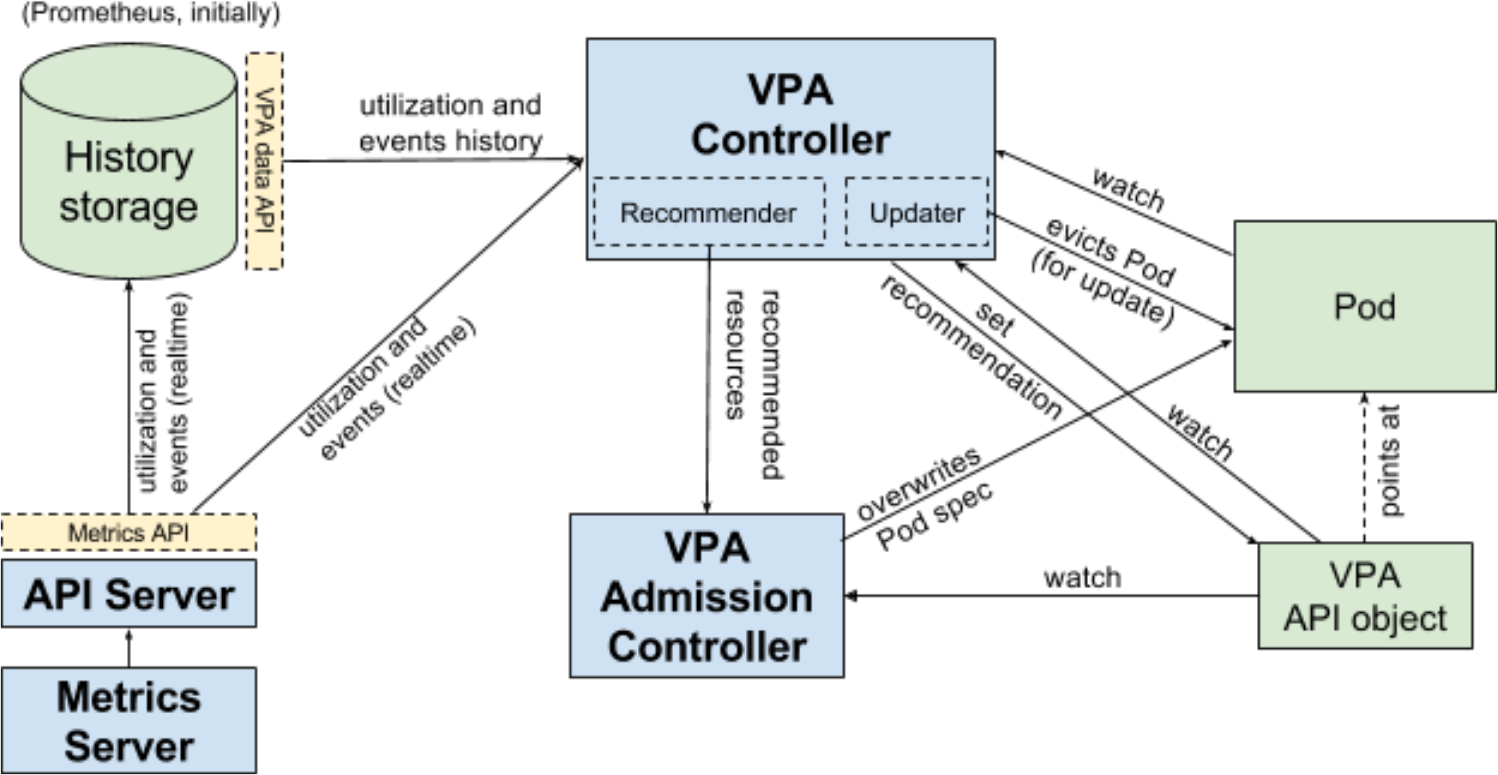
- Recommender,负责计算一个 VPA 对象中所匹配 Pod 的资源推荐值
- Admission Controller,负责拦截所有 Pod 的创建请求,并覆盖匹配到 VPA 对象的 Pod 资源值字段
- Updater,负责 Pod 资源的实时更新
Recommender
Autoscaler 的 VPA Recommender 以 Deployment 形式部署。并且在VerticalPodAutoscalerCRD 的 spec 中,可以通过Recommenders字段指定一个或多个 VPA Recommender(默认使用名为default的 VPA Recommender)。
VPA Recommender 对应的内部结构组成如下所示,其中:
// vertical-pod-autoscaler/pkg/recommender/main.go
recommender := routines.RecommenderFactory{
ClusterState: clusterState,
ClusterStateFeeder: clusterStateFeeder,
ControllerFetcher: controllerFetcher,
CheckpointWriter: checkpoint.NewCheckpointWriter(clusterState, vpa_clientset.NewForConfigOrDie(config).AutoscalingV1()),
VpaClient: vpa_clientset.NewForConfigOrDie(config).AutoscalingV1(),
PodResourceRecommender: logic.CreatePodResourceRecommender(),
CheckpointsGCInterval: *checkpointsGCInterval, // 由 --checkpoints-gc-interval 参数指定,默认 10min
UseCheckpoints: useCheckpoints,
// ...
}.Make()
ClusterState表示整个集群的资源状态,主要由 Pod 的状态和 VPA 的状态组成,充当了一个本地缓存的角色ClusterStateFeeder定义了一系列集群资源状态的获取方式,这些获取的资源状态最终会存储在ClusterState中。它们包括但不限于:- Pod Lister,Pod 资源的 Informer,负责监听指定命名空间下(默认“所有”)非
pending状态的 Pod - VPA Lister,由 Autoscaler 定义的一个多版本(包括 v1、v1beta1、v1beta2 等)client,其中每个版本的 client 本质上对应的还是 k8s client,默认使用 v1 版本
- OOM Observer,本质上为一个缓冲为 5000(固定值)的通道,其存储了有关 OOM Event 的所有元数据信息,它通过监听指定命名空间下(默认“所有”)所有
reason=Evicted类型的事件来获取数据并写入通道 - Controller Fetcher,各种 k8s 控制器的 Informer,监听了所有能够控制 Pod 资源调谐的控制器,包括 Deployment、DaemonSet、ReplicaSet、Job 等
- Metrics Client,作为 Metric Server 的客户端以获取集群中 Pod 的 Metrics
- Pod Lister,Pod 资源的 Informer,负责监听指定命名空间下(默认“所有”)非
ControllerFetcher的定义同上述 Controller FetcherVpaClient的定义同上述 VPA ListerPodResourceRecommender的定义见下文Estimator章节- Checkpoints 是集群资源历史状态在本地磁盘的持久化存储,VPA Recommender 支持导入该数据以计算 Pod Resources 的推荐值
Estimator
Pod Resources 的推荐值算子(Estimator)是由PodResourceRecommender函数初始化的。该函数初始化了三个 Estimator:TargetEstimator、LowerBoundEstimator和UpperBoundEstimator,分别表示推荐资源的目标值及可行域范围。Estimator 共有四种算子,如下图所示。
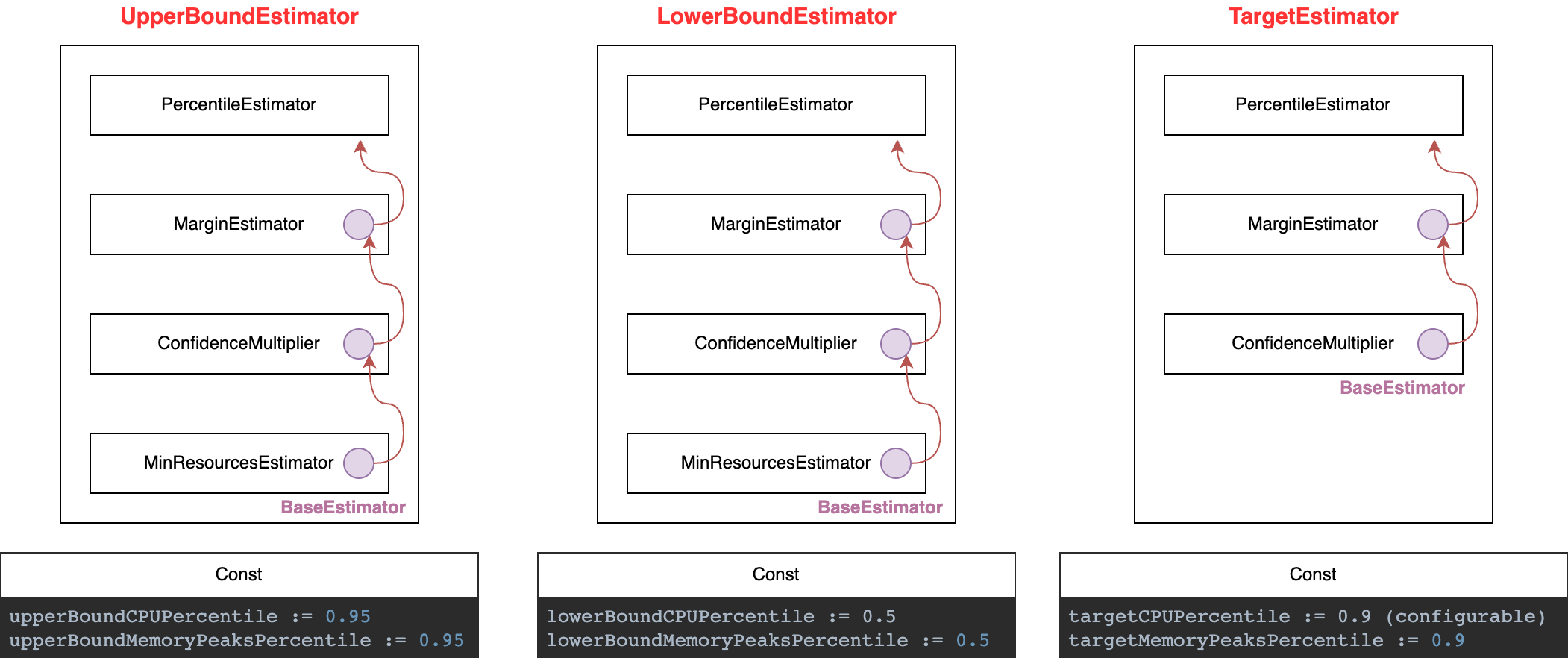
每个 Estimator 的计算顺序都为自顶向下。以PercentileEstimator为例,其作为MarginEstimator的baseEstimator使用,它会根据每个 container 的一组状态(作为分布)计算出 CPU 和内存在该分布 Percentile 位置(比如 95 分位点)的取值作为输出。CPU 和 Memory Peaks 的 Percentile 作为常数值出现,其中只有targetCPUPercentile可以配置,其他都是固定值。
执行流程
Recommender 定期执行一次推荐资源值的计算,执行周期可由--recommender-interval参数指定,默认为 1 min。
执行期间,首先通过ClusterStateFeeder加载 VPA、Pod 资源和实时 Metrics 到ClusterState。以加载 VPA 资源为例,它是一个全量加载的过程:
// vertical-pod-autoscaler/pkg/recommender/input/cluster_feeder.go
func (feeder *clusterStateFeeder) LoadVPAs() {
// 获取所有 VPA API 对象
allVpaCRDs, err := feeder.vpaLister.List(labels.Everything())
// 过滤出 Filter out VPAs that specified recommenders with names not equal to "default"
vpaCRDs := filterVPAs(feeder, allVpaCRDs)
// ... 根据 vpaCRDs 的结果,更新/增加/删除 ClusterState.Vpas
feeder.clusterState.ObservedVpas = vpaCRDs
}
func filterVPAs(feeder *clusterStateFeeder, allVpaCRDs []*vpa_types.VerticalPodAutoscaler) []*vpa_types.VerticalPodAutoscaler {
var vpaCRDs []*vpa_types.VerticalPodAutoscaler
for _, vpaCRD := range allVpaCRDs {
if feeder.recommenderName == DefaultRecommenderName { // 若 Recommender 名为 default,
// 则跳过那些指定了其他 Recommender 且不包含名为 default Recommender 的 VPA
// 对于未指定任何 Recommender 的 VPA,其默认使用 default Recommender
if !implicitDefaultRecommender(vpaCRD.Spec.Recommenders) && !selectsRecommender(vpaCRD.Spec.Recommenders, &feeder.recommenderName) {
continue
}
} else {
// 对于其他指定名称的 Recommender,其不能作为任何无指定 VPA Recommenders 的默认 Recommender
if implicitDefaultRecommender(vpaCRD.Spec.Recommenders) {
continue
}
// 只有在 Recommender 与 VPA Recommenders 存在匹配时,该 VPA 才生效
if !selectsRecommender(vpaCRD.Spec.Recommenders, &feeder.recommenderName) {
continue
}
}
vpaCRDs = append(vpaCRDs, vpaCRD)
}
return vpaCRDs
}
最后 Recommender 调用UpdateVPAs方法计算 Pod Resources 的推荐值并写入至 VPA 对象。
// vertical-pod-autoscaler/pkg/recommender/routines/recommender.go
func (r *recommender) UpdateVPAs() {
// ...
for _, observedVpa := range r.clusterState.ObservedVpas { // 通过 LoadVPAs() 获取
key := model.VpaID{
Namespace: observedVpa.Namespace,
VpaName: observedVpa.Name,
}
vpa, found := r.clusterState.Vpas[key]
if !found {
continue
}
resources := r.podResourceRecommender.GetRecommendedPodResources(GetContainerNameToAggregateStateMap(vpa)) // 通过 Estimator 计算资源推荐值
listOfResourceRecommendation := logic.MapToListOfRecommendedContainerResources(resources)
vpa.UpdateRecommendation(listOfResourceRecommendation) // 将推荐值写入 VPA
hasMatchingPods := vpa.PodCount > 0
vpa.UpdateConditions(hasMatchingPods) // 更新 VPA conditions
err := r.clusterState.RecordRecommendation(vpa, time.Now()) // 将推荐值也写入到 ClusterState
_, err := vpa_utils.UpdateVpaStatusIfNeeded(r.vpaClient.VerticalPodAutoscalers(vpa.ID.Namespace), vpa.ID.VpaName,
vpa.AsStatus() /* new status */, &observedVpa.Status /* old status */) // 更新 VPA Status
}
}
Admission Controller
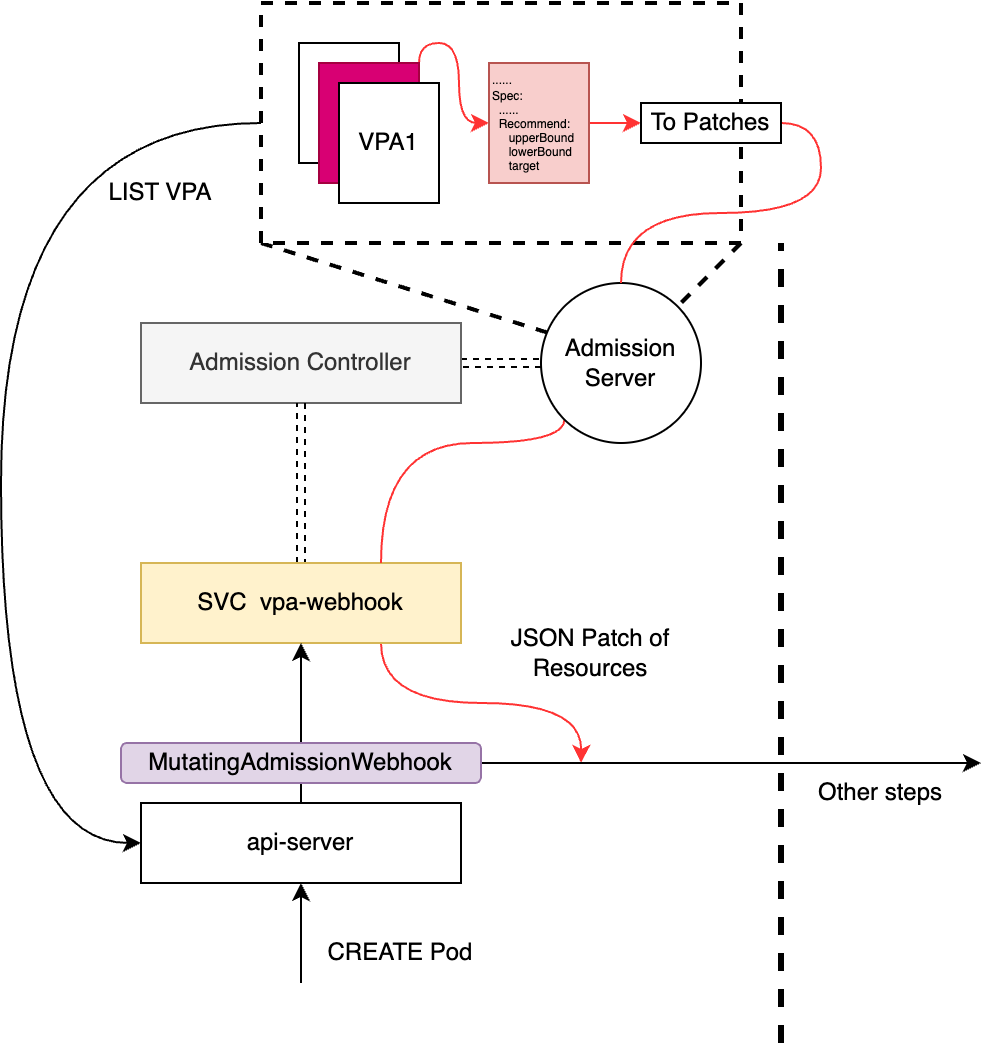
Autoscaler 的 VPA Admission Controller 以 Deplyments 形式部署,并默认在kube-system命名空间下以名为vpa-webhook的 Service 提供 HTTPS 服务。
Admission Controller 的整体执行过程如下代码所示(大致过程可参考上图):
- 它主要负责创建并启动 Admission Server
- 注册 Pod 和 VPA 资源的 Handler,负责处理各自对应资源的创建请求
- 注册 Calculator,以获取 Recommender 中计算的资源推荐值;这里注册了两个 Calculator,其中第一个就是从 VPA CRD 的 Recommend 字段获取推荐值,第二个是为每个 Pod 都添加一个
vpaObservedContainers: {container_name1, ...}风格的 annotations - 注册 Webhook,以拦截相关资源的创建请求,详细描述见下文
// vertical-pod-autoscaler/pkg/admission-controller/main.go
func main() {
// ...
vpaClient := vpa_clientset.NewForConfigOrDie(config)
vpaLister := vpa_api_util.NewVpasLister(vpaClient, make(chan struct{}), *vpaObjectNamespace) // 同上文 VPA Lister
kubeClient := kube_client.NewForConfigOrDie(config)
factory := informers.NewSharedInformerFactory(kubeClient, /* defaultResyncPeriod=10min */)
targetSelectorFetcher := target.NewVpaTargetSelectorFetcher(config, kubeClient, factory) // 同上文的 Controller Fetcher
recommendationProvider := recommendation.NewProvider(/* ... */) // 推荐资源值的提供方
vpaMatcher := vpa.NewMatcher(vpaLister, targetSelectorFetcher)
calculators := []patch.Calculator{patch.NewResourceUpdatesCalculator(recommendationProvider), patch.NewObservedContainersCalculator()}
as := logic.NewAdmissionServer(/* ... */, vpaMatcher, calculators) // 创建 Server
\
\
as := &AdmissionServer{/* ... */, map[metav1.GroupResource]resource.Handler{}}
as.RegisterResourceHandler(pod.NewResourceHandler(/* ... */, vpaMatcher, calculators)) // 注册 Resource Handler
as.RegisterResourceHandler(vpa.NewResourceHandler(/* ... */))
http.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {
as.Serve(w, r) // 处理拦截到的请求
})
server := &http.Server{
Addr: fmt.Sprintf(":%d", *port),
TLSConfig: configTLS(certs.serverCert, certs.serverKey),
}
go func() {
selfRegistration(kubeClient, certs.caCert, namespace, *serviceName, url, *registerByURL, int32(*webhookTimeout)) // 将自己注册为 MutatingAdmissionWebhook
}()
err = server.ListenAndServeTLS("", "") // 开启 HTTPS 服务
}
Webhook 注册
Admission Controller 通过selfRegistration函数将自己提供的服务注册为了一个MutatingAdmissionWebhook。观察该 Webhook 的配置可以发现,其只在对应 Pod 事件为 CREATE、对应 VPA 事件为 CREATE 或 UPDATE 时生效。
// vertical-pod-autoscaler/pkg/admission-controller/config.go
func selfRegistration(clientset *kubernetes.Clientset, caCert []byte, namespace, serviceName, url string, registerByURL bool, timeoutSeconds int32) {
time.Sleep(10 * time.Second) // ...等会儿开始
client := clientset.AdmissionregistrationV1().MutatingWebhookConfigurations()
// 已有的 webhook 要删除重建
_, err := client.Get(context.TODO(), "vpa-webhook-config", metav1.GetOptions{})
if err == nil {
err2 := client.Delete(context.TODO(), "vpa-webhook-config", metav1.DeleteOptions{})
}
RegisterClientConfig := admissionregistration.WebhookClientConfig{}
RegisterClientConfig.Service = &admissionregistration.ServiceReference{ // 与 webhook 建立 TLS 连接的服务信息
Namespace: namespace,
Name: serviceName,
}
RegisterClientConfig.CABundle = caCert
webhookConfig := &admissionregistration.MutatingWebhookConfiguration{
ObjectMeta: metav1.ObjectMeta{
Name: "vpa-webhook-config",
},
Webhooks: []admissionregistration.MutatingWebhook{
{
Name: "vpa.k8s.io",
AdmissionReviewVersions: []string{"v1"},
Rules: []admissionregistration.RuleWithOperations{
{
Operations: []admissionregistration.OperationType{"CREATE"},
Rule: admissionregistration.Rule{
APIGroups: []string{""},
APIVersions: []string{"v1"},
Resources: []string{"pods"},
},
},
{
Operations: []admissionregistration.OperationType{"CREATE", "UPDATE"},
Rule: admissionregistration.Rule{
APIGroups: []string{"autoscaling.k8s.io"},
APIVersions: []string{"*"},
Resources: []string{"verticalpodautoscalers"},
},
},
},
FailurePolicy: "Ignore",
ClientConfig: RegisterClientConfig,
SideEffects: "None",
TimeoutSeconds: &timeoutSeconds,
},
},
}
_, err := client.Create(context.TODO(), webhookConfig, metav1.CreateOptions{})
}
Admit
Pod 的创建请求(或 VPA 的创建/更新请求)都会被上述MutatingAdmissionWebhook拦截并转发到 Admission Controller Server 提供的服务中,该 Server 通过Serve方法处理接收到的创建(或更新)请求。
// vertical-pod-autoscaler/pkg/admission-controller/logic/server.go
func (s *AdmissionServer) Serve(w http.ResponseWriter, r *http.Request) {
var body []byte // 读取请求数据
if r.Body != nil {
if data, err := io.ReadAll(r.Body); err == nil {
body = data
}
}
contentType := r.Header.Get("Content-Type") // 请求体必须是 JSON 格式的
if contentType != "application/json" {
return
}
reviewResponse, status, resource := s.admit(body) // 组织响应内容
ar := v1.AdmissionReview{
Response: reviewResponse,
TypeMeta: metav1.TypeMeta{
Kind: "AdmissionReview",
APIVersion: "admission.k8s.io/v1",
},
}
resp, err := json.Marshal(ar)
_, err = w.Write(resp) // 写回响应
}
针对每一个请求的响应都是通过 Admission Server 的admit方法来构建的,响应体中的数据就是对该请求资源的JSON Patches:
// vertical-pod-autoscaler/pkg/admission-controller/logic/server.go
func (s *AdmissionServer) admit(data []byte) (*v1.AdmissionResponse, metrics_admission.AdmissionStatus, metrics_admission.AdmissionResource) {
response := v1.AdmissionResponse{}
ar := v1.AdmissionReview{}
err := json.Unmarshal(data, &ar) // 解析请求数据
var patches []resource.PatchRecord
admittedGroupResource := metav1.GroupResource{
Group: ar.Request.Resource.Group,
Resource: ar.Request.Resource.Resource,
}
handler, ok := s.resourceHandlers[admittedGroupResource] // 获取该请求对应资源的 Handler
if ok {
patches, err = handler.GetPatches(ar.Request) // 返回对应资源的 json patches
resource = handler.AdmissionResource()
}
if len(patches) > 0 {
patch, err := json.Marshal(patches) // 编码响应数据
response.PatchType = "JSONPatch"
response.Patch = patch
}
// ... 计算 status
return &response, status, resource
}
以 Pod 资源为例,其 Handler 对应的GetPatches方法如下:
// vertical-pod-autoscaler/pkg/admission-controller/resource/pod/handler.go
func (h *resourceHandler) GetPatches(ar *admissionv1.AdmissionRequest) ([]resource_admission.PatchRecord, error) {
raw, namespace := ar.Object.Raw, ar.Namespace
pod := v1.Pod{}
err := json.Unmarshal(raw, &pod)
// ...
controllingVpa := h.vpaMatcher.GetMatchingVPA(&pod) // 获取控制该 Pod 的 VPA 资源
patches := []resource_admission.PatchRecord{}
for _, c := range h.patchCalculators {
partialPatches, err := c.CalculatePatches(&pod, controllingVpa) // 根据每种 calculator 的计算方式返回 patch
patches = append(patches, partialPatches...)
}
return patches, nil
}
Updater
Autoscaler 的 Updater 以 Deployment 形式默认在kube-system命名空间下部署。Updater 用于决定哪些 Pods 需要根据 Recommender 计算的值调整资源,Updater 对 Pod 的资源调整采用驱逐再重建的方式(同时也考虑了 Pod Disruption Budget)。Updater 自身并没有资源更新的能力,而是只负责驱逐 Pod,再次创建 Pod 时资源更新的能力则依赖于 Admission Controller。
Updater 的关键结构如下所示。它是一个无限运行的循环,资源更新的执行周期默认为 1 min。
// vertical-pod-autoscaler/pkg/updater/main.go
updater, err := updater.NewUpdater(
kubeClient,
vpaClient,
*minReplicas, // default=2
*evictionToleranceFraction, // default=0.5,在多于一个 Pod 时,能够被驱逐的 Pod 比例
*useAdmissionControllerStatus, // 只在 admission controller 状态正常时才启用 updater
admissionControllerStatusNamespace, // admission controller 所在的命名空间,默认为 kube-system
/* evictionAdmission: */ nil,
vpa_api_util.NewCappingRecommendationProcessor(), // 负责调整 Pod 内的资源值,使其遵循 VPA 的 Resource Policy 和容器 Limit
targetSelectorFetcher,
priority.NewProcessor(), // 处理驱逐优先级相关逻辑
*vpaObjectNamespace, // 查询 VPA 对象的命名空间,默认所有
// ...
)
每次资源更新调用的都是 Updater 的RunOnce方法,该方法会枚举每个 VPA 资源及其对应的 Pods,筛选出在当前 VPA 中需要进行资源更新的 Pods 并对它们逐一进行驱逐。
// vertical-pod-autoscaler/pkg/updater/logic/updater.go
func (u *updater) RunOnce(ctx context.Context) {
if u.useAdmissionControllerStatus {
isValid, err := u.statusValidator.IsStatusValid(status.AdmissionControllerStatusTimeout) // 检查 Admission Controller 状态是否正常
if !isValid {
return
}
}
vpaList, err := u.vpaLister.List(labels.Everything()) // 列出所有 VPA 资源
vpas := make([]*vpa_api_util.VpaWithSelector, 0)
for _, vpa := range vpaList {
if vpa_api_util.GetUpdateMode(vpa) != vpa_types.UpdateModeRecreate &&
vpa_api_util.GetUpdateMode(vpa) != vpa_types.UpdateModeAuto { // Updater 只在 "Recreate" 或 "Auto" 模式下生效
continue
}
selector, err := u.selectorFetcher.Fetch(vpa)
vpas = append(vpas, &vpa_api_util.VpaWithSelector{
Vpa: vpa,
Selector: selector,
})
}
podsList, err := u.podLister.List(labels.Everything()) // 列出所有 Pod 资源
allLivePods := filterDeletedPods(podsList) // 过滤掉所有被删除的 Pod(即 DeletionTimestamp 不为空的)
controlledPods := make(map[*vpa_types.VerticalPodAutoscaler][]*apiv1.Pod)
for _, pod := range allLivePods {
controllingVPA := vpa_api_util.GetControllingVPAForPod(pod, vpas) // 获取当前 Pod 对应的 VPA 资源
if controllingVPA != nil {
controlledPods[controllingVPA.Vpa] = append(controlledPods[controllingVPA.Vpa], pod)
}
}
for vpa, livePods := range controlledPods {
evictionLimiter := u.evictionFactory.NewPodsEvictionRestriction(livePods, vpa)
podsForUpdate := u.getPodsUpdateOrder(filterNonEvictablePods(livePods, evictionLimiter), vpa) // 获取需要进行资源更新的 Pod 以进行驱逐
for _, pod := range podsForUpdate {
if !evictionLimiter.CanEvict(pod) { // 判断是否能驱逐
continue
}
evictErr := evictionLimiter.Evict(pod, u.eventRecorder) // 执行驱逐
}
}
}
优先级处理
Updater 通过getPodsUpdateOrder方法返回一个需要资源更新的 Pods 列表,列表中的 Pod 是按照更新优先级从高到低排列的。
// vertical-pod-autoscaler/pkg/updater/logic/updater.go
func (u *updater) getPodsUpdateOrder(pods []*apiv1.Pod, vpa *vpa_types.VerticalPodAutoscaler) []*apiv1.Pod {
priorityCalculator := priority.NewUpdatePriorityCalculator(vpa, nil, u.recommendationProcessor, u.priorityProcessor)
for _, pod := range pods {
priorityCalculator.AddPod(pod, time.Now()) // 添加 Pod 并进行一次优先级计算
}
return priorityCalculator.GetSortedPods(u.evictionAdmission) // 按照 Pod 的优先级(ResourceDiff)降序排序
}
AddPod方法用来收集可以进行资源更新的 Pod 对象,这里除了判断更新的资源值是否在推荐值合理范围(OutsideRecommendedRange)内、更新的资源值是否不变(ResourceDiff == 0)因素外,还考虑了 Pod 中容器是否有短时间内的 OOM 发生(quick OOM,因为短期内发生了 OOM 证明容器资源设置的过低,急需扩容)。
// vertical-pod-autoscaler/pkg/updater/priority/update_priority_calculator.go
func (calc *UpdatePriorityCalculator) AddPod(pod *apiv1.Pod, now time.Time) {
processedRecommendation, _, err := calc.recommendationProcessor.Apply(calc.vpa.Status.Recommendation, calc.vpa.Spec.ResourcePolicy, calc.vpa.Status.Conditions, pod) // 获取资源推荐值
hasObservedContainers, vpaContainerSet := parseVpaObservedContainers(pod) // 通过解析 Pod annotation 中的 vpaObservedContainers 字段对应的值,以获取该 Pod 中被 Admission Controller 观察的容器集合
updatePriority := calc.priorityProcessor.GetUpdatePriority(pod, calc.vpa, processedRecommendation) // 计算更新的优先级
// 开始快速 OOM 的判断逻辑
quickOOM := false
for i := range pod.Status.ContainerStatuses {
cs := &pod.Status.ContainerStatuses[i]
if hasObservedContainers && !vpaContainerSet.Has(cs.Name) { // 对于没有被 Admission Controller 观察到的容器,是不支持快速 OOM 判断的
continue
}
crp := vpa_api_util.GetContainerResourcePolicy(cs.Name, calc.vpa.Spec.ResourcePolicy)
if crp != nil && crp.Mode != nil && *crp.Mode == vpa_types.ContainerScalingModeOff { // 对于 ResourcePolicy 为 ContainerScalingModeOff 的情况,也忽略快速 OOM 判断逻辑
continue
}
terminationState := &cs.LastTerminationState
if terminationState.Terminated != nil && terminationState.Terminated.Reason == "OOMKilled" &&
terminationState.Terminated.FinishedAt.Time.Sub(terminationState.Terminated.StartedAt.Time) < *evictAfterOOMThreshold /* 默认 10 min */ {
quickOOM = true // 对于上次终止状态来说,若其产生原因为 OOM 并且持续时间小于一定阈值,则认为是快速的 OOM
}
}
if !updatePriority.OutsideRecommendedRange && !quickOOM {
// 处理几种正常情况下的一些异常情况,若出现则直接 return
// ...
}
// 对于经历过快速 OOM 并且资源值不变的情况,则直接返回
if quickOOM && updatePriority.ResourceDiff == 0 {
return
}
calc.pods = append(calc.pods, prioritizedPod{
pod: pod,
priority: updatePriority,
recommendation: processedRecommendation})
}
更新的资源值是通过GetUpdatePriority方法计算的,其返回值类型PodPriority中的ResourceDiff表示了所有资源类型差值(请求值与推荐值差的绝对值)的归一化总和。后续在对 Pod 进行更新优先级排序时,ResourceDiff就是排序所使用的基准。
// vertical-pod-autoscaler/pkg/updater/priority/priority_processor.go
func (*defaultPriorityProcessor) GetUpdatePriority(pod *apiv1.Pod, _ *vpa_types.VerticalPodAutoscaler,
recommendation *vpa_types.RecommendedPodResources) PodPriority {
outsideRecommendedRange := false
scaleUp := false
totalRequestPerResource := make(map[apiv1.ResourceName]int64) // 请求资源的总值,按资源类型分类
totalRecommendedPerResource := make(map[apiv1.ResourceName]int64) // 推荐资源的总值,按资源类型分类
hasObservedContainers, vpaContainerSet := parseVpaObservedContainers(pod) // 函数同上
for _, podContainer := range pod.Spec.Containers {
if hasObservedContainers && !vpaContainerSet.Has(podContainer.Name) { // 只对被 Admission Controller 观察到的容器生效
continue
}
recommendedRequest := vpa_api_util.GetRecommendationForContainer(podContainer.Name, recommendation) // 获取该容器对应的推荐值
if recommendedRequest == nil {
continue
}
for resourceName, recommended := range recommendedRequest.Target {
totalRecommendedPerResource[resourceName] += recommended.MilliValue()
lowerBound, hasLowerBound := recommendedRequest.LowerBound[resourceName]
upperBound, hasUpperBound := recommendedRequest.UpperBound[resourceName]
if request, hasRequest := podContainer.Resources.Requests[resourceName]; hasRequest { // 判断几种边界情况:
totalRequestPerResource[resourceName] += request.MilliValue()
if recommended.MilliValue() > request.MilliValue() { // 1.是否扩容
scaleUp = true
}
if (hasLowerBound && request.Cmp(lowerBound) < 0) ||
(hasUpperBound && request.Cmp(upperBound) > 0) { // 2.是否越界
outsideRecommendedRange = true
}
} else {
scaleUp = true
outsideRecommendedRange = true
}
}
}
resourceDiff := 0.0 // 所有资源类型差值的总和
for resource, totalRecommended := range totalRecommendedPerResource {
totalRequest := math.Max(float64(totalRequestPerResource[resource]), 1.0)
resourceDiff += math.Abs(totalRequest-float64(totalRecommended)) / totalRequest // 对每种资源类型差值都进行了归一化
}
return PodPriority{
OutsideRecommendedRange: outsideRecommendedRange,
ScaleUp: scaleUp,
ResourceDiff: resourceDiff,
}
}
Evict
对于每一个需要更新资源值的 Pod,Updater 都会先检测该 Pod 是否能被驱逐,若能,则将其驱逐;若不能,则跳过此次驱逐。
Updater 对 Pod 是否能够被驱逐的判断是通过CanEvict方法来完成的。它既保证了一个 Pod 对应的 Controller 只能驱逐可容忍范围内的 Pod 副本数,又保证了该副本数不会为 0(至少为 1)。
// vertical-pod-autoscaler/pkg/updater/eviction/pods_eviction_restriction.go
func (e *podsEvictionRestrictionImpl) CanEvict(pod *apiv1.Pod) bool {
cr, present := e.podToReplicaCreatorMap[getPodID(pod)] // 根据 pod ID 找到其控制器
if present {
singleGroupStats, present := e.creatorToSingleGroupStatsMap[cr]
if pod.Status.Phase == apiv1.PodPending {
return true // 对于处于 Pending 状态的 Pod,可以被驱逐
}
if present {
shouldBeAlive := singleGroupStats.configured - singleGroupStats.evictionTolerance // 由 evictionToleranceFraction 控制,表示最多能驱逐的副本数
if singleGroupStats.running-singleGroupStats.evicted > shouldBeAlive {
return true // 对于可容忍的驱逐数量之内,可以被驱逐
}
if singleGroupStats.running == singleGroupStats.configured &&
singleGroupStats.evictionTolerance == 0 &&
singleGroupStats.evicted == 0 {
return true // 若所有 Pods 都在运行,并且可容忍的驱逐数量过小,则只可以驱逐一个
}
}
}
return false
}
Evict函数负责对一个 Pod 进行驱逐,使用的是policy/v1 Group 下的 API,可以对目的 Pod 发送一个驱逐请求。
// vertical-pod-autoscaler/pkg/updater/eviction/pods_eviction_restriction.go
func (e *podsEvictionRestrictionImpl) Evict(podToEvict *apiv1.Pod, eventRecorder record.EventRecorder) error {
cr, present := e.podToReplicaCreatorMap[getPodID(podToEvict)]
if !e.CanEvict(podToEvict) { // 再次判断 Pod 是否可被驱逐
return
}
eviction := &policyv1.Eviction{
ObjectMeta: metav1.ObjectMeta{
Namespace: podToEvict.Namespace,
Name: podToEvict.Name,
},
}
err := e.client.CoreV1().Pods(podToEvict.Namespace).EvictV1(context.TODO(), eviction) // 触发驱逐事件
if podToEvict.Status.Phase != apiv1.PodPending {
singleGroupStats, present := e.creatorToSingleGroupStatsMap[cr]
singleGroupStats.evicted = singleGroupStats.evicted + 1 // 增加相应的驱逐次数
e.creatorToSingleGroupStatsMap[cr] = singleGroupStats
}
return nil
}
总结
Autoscaler 是 Kubernetes 社区维护的一个集群自动化扩缩容工具库,VPA 只是其中的一个模块。目前许多公有云的 VPA 实现,也都与 Autoscaler 的 VPA 实现类似,比如 GKE 等。但 GKE 相比 Autoscaler 还存在一些改进:
- 在资源推荐值计算时,额外考虑了支持最大节点数与单节点资源限额
- VPA 能够通知 Cluster Autoscaler 来调整集群容量
- 将 VPA 作为一个控制面的进程,而非 Worker 节点中的 Deployments
Autoscaler 的 VPA 是基于对 Pod 的驱逐重建完成的,在部分对驱逐敏感的场景下,Autoscaler 其实并不能很好的胜任 VPA 工作。面对这种场景,就需要一种可以原地更新 Pod 资源的技术。
资源原地更新
此部分内容对应的代码基于 Kubernetes HEAD 4c18d40 和 containerd HEAD 03e4f1e。
Pod 资源的原地(In-Place)更新主要指原地更新 Pod Resources 的 request 和 limit 值。在 K8s 中,该功能由 KEP-1287 引入,并由 PR #102884 实现。该功能对应的大致流程如下所示:
+-----------+ +-----------+ +-----------+
| | | | | |
| apiserver | | kubelet | | runtime |
| | | | | |
+-----+-----+ +-----+-----+ +-----+-----+
| | |
| watch (pod update) | |
|------------------------------>| |
| [Containers.Resources] | |
| | |
| (admit) |
| | |
| | UpdateContainerResources() |
| |----------------------------->|
| | (set limits)
| |<- - - - - - - - - - - - - - -|
| | |
| | ContainerStatus() |
| |----------------------------->|
| | |
| | [ContainerResources] |
| |<- - - - - - - - - - - - - - -|
| | |
| update (pod status) | |
|<------------------------------| |
| [ContainerStatuses.Resources] | |
| | |
在 K8s 中,一个新创建的 Pod,其Pod.Spec.Containers[i].AllocatedResources字段是由 api-server 设置的,用以匹配每个容器所请求的资源Pod.Spec.Containers[i].Resources.Requests。当 kubelet 准备创建一个 Pod 时,它会根据 Pod 的AllocatedResources字段来判断当前节点是否还能容纳此 Pod。
当一个 Pod 发生 Resize 时,kubelet 会尝试更新其内部容器资源的分配值。kubelet 首先检查新的期望资源值是否超过了当前节点的资源可用值,若资源不合适,则返回Infeasible状态;若资源合适但 Pod 不可用,则返回Deferred状态;若资源合适则返回InProgress状态。
// kubernetes/pkg/kubelet/kubelet.go
func (kl *Kubelet) canResizePod(pod *v1.Pod) (bool, *v1.Pod, v1.PodResizeStatus) {
var otherActivePods []*v1.Pod
node, err := kl.getNodeAnyWay()
podCopy := pod.DeepCopy()
cpuAvailable := node.Status.Allocatable.Cpu().MilliValue()
memAvailable := node.Status.Allocatable.Memory().Value()
cpuRequests := resource.GetResourceRequest(podCopy, v1.ResourceCPU)
memRequests := resource.GetResourceRequest(podCopy, v1.ResourceMemory)
if cpuRequests > cpuAvailable || memRequests > memAvailable {
return false, podCopy, v1.PodResizeStatusInfeasible
}
activePods := kl.GetActivePods() // 处于 Terminal 状态的 Pods 属于 Inactive
for _, p := range activePods {
if p.UID != pod.UID {
otherActivePods = append(otherActivePods, p) // 收集非 Active 的 Pods
}
}
if ok, failReason, failMessage := kl.canAdmitPod(otherActivePods, podCopy); !ok {
return false, podCopy, v1.PodResizeStatusDeferred
}
// ...
return true, podCopy, v1.PodResizeStatusInProgress
}
kubelet 是通过调用 CRI 中 ContainerManager 的UpdateContainerResources API 来更新对应容器的 CPU 和内存 Limits 值的。在 containerd 中,该 API 对应的实现如下所示。其通过 NRI 提供的UpdateContainerResources API 来完成真正的资源更新操作。
// containerd/pkg/cri/server/container_update_resources.go
func (c *criService) UpdateContainerResources(ctx context.Context, r *runtime.UpdateContainerResourcesRequest) (retRes *runtime.UpdateContainerResourcesResponse, retErr error) {
container, err := c.containerStore.Get(r.GetContainerId()) // 获取目标 container
sandbox, err := c.sandboxStore.Get(container.SandboxID) // 获取 container 所在 sandbox
resources := r.GetLinux()
updated, err := c.nri.UpdateContainerResources(ctx, &sandbox, &container, resources) // 通过 nri 更新容器资源配置
if updated != nil {
*resources = *updated
}
err := container.Status.UpdateSync(func(status containerstore.Status) (containerstore.Status, error) { // 更新资源状态
return c.updateContainerResources(ctx, container, r, status)
})
return &runtime.UpdateContainerResourcesResponse{}, nil
}
热迁移与 VPA
在今年的 KubeCon 2023 Asia Shanghai 分享了一个议题《在 Kubernetes 生产环境中的容器实时迁移》,也提到了 VPA 现在面临的一个痛点:在当前节点资源不足时,就无法再支撑 Pod 的垂直扩容。这个问题比较好的解决方案就是容器的热迁移(又称实时迁移)。
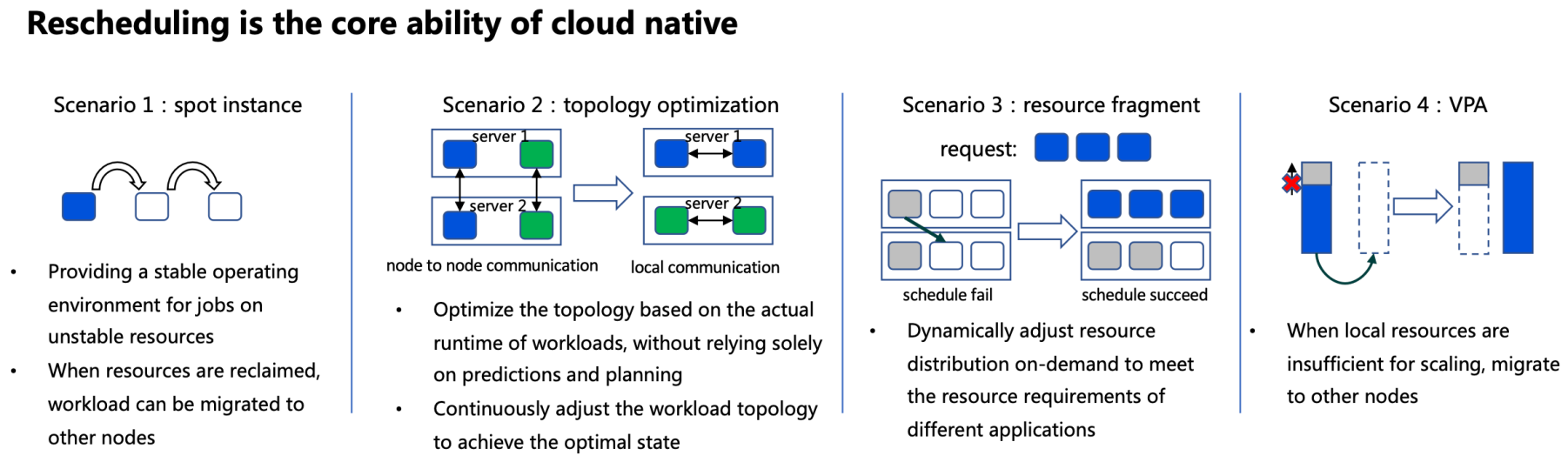
分享者表示,容器的实时迁移(Rescheduling,但不同于普通的重调度,这里要求容器在重新调度后,容器的状态还继续保持调度前的状态,例如用户数据、容器状态等等)在云原生场景下的应具备以下几点核心能力:
- 基本的 Reschedule 能力,工作负载可以从一个节点实时迁移到另外一个节点去
- 拓扑优化能力,根据工作负载真正运行的位置来通过实时迁移优化其拓扑结构,而非单纯靠提前的规划与预测能力(这里对比的是 K8s 中的调度器,可以理解为调度是一个一次性的操作,而集群的资源是一个动态变化的环境,所以能够实时的根据集群的资源变化动态调整/迁移负载变得尤为重要)
- 资源碎片调整能力,动态的对集群资源进行调整,以适配不同的资源请求,避免每个节点都只被请求了部分资源,造成资源碎片的产生
这里的最后一点能力表示:VPA 面临节点资源不足,无法再进行资源申请的情况下,也可以通过热迁移来为节点“腾出”资源以保证 VPA 的顺利进行。
Reference
- https://github.com/kubernetes/autoscaler/tree/master/vertical-pod-autoscaler
- https://github.com/kubernetes/design-proposals-archive/blob/main/autoscaling/vertical-pod-autoscaler.md
- https://github.com/kubernetes/enhancements/tree/master/keps/sig-node/1287-in-place-update-pod-resources
- https://cloud.google.com/kubernetes-engine/docs/concepts/verticalpodautoscaler
- https://static.sched.com/hosted_files/kccncosschn2023/d1/live%20migration-eng.pdf