Merbridge: 基于 eBPF 加速 Istio 的流量转发能力
本文代码基于 Merbridge HEAD c16cc43 展开。
简介
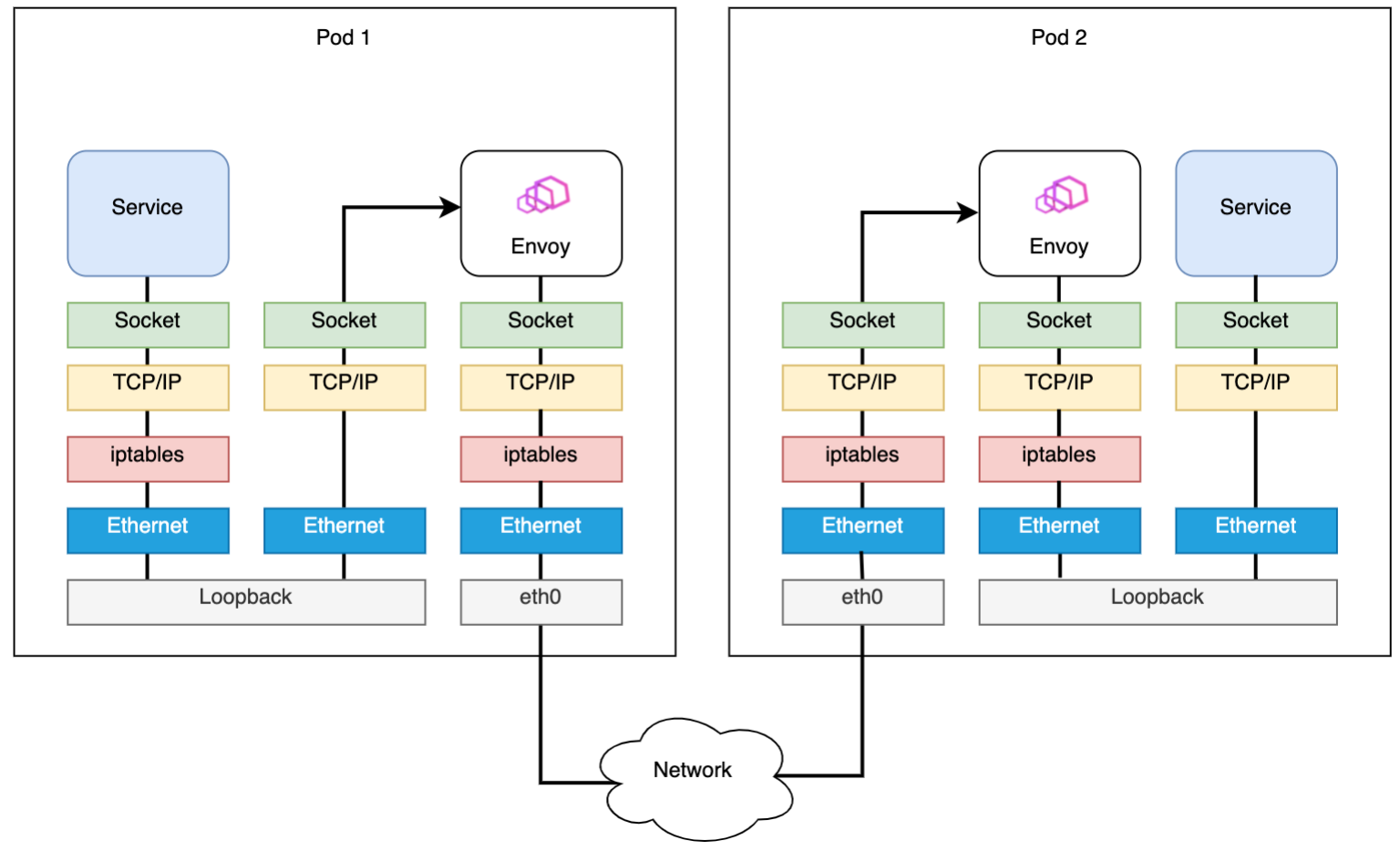
Merbridge 是基于 eBPF 实现的一套可用于服务网格中流量拦截与高性能转发的方案,其支持多种服务网格项目(Istio、Kuma、Linkerd 等)适配,本文只以 Istio Sidecar 模式为例展开。
具体来讲(以 Istio Sidecar 模式为例),下图为原始流量路径:
2023 年度总结
与其说这是 2023 年的年度总结,不如说这是癸卯年的年度总结,鉴于并不是在公历新年写的。想着既然在 GitHub 开了自己的博客,那就将就着碎碎念一下吧。(点了根烟,开始发挥
博客初衷
从今年五月份的时候开始搭建的这个博客平台,没有用自己服务器,也没有申请专属的域名,而是图着省事直接用 GitHub.io 来的。
当时这个时间节点,是听到左耳朵耗子叔离世🕯️的消息,便开始着手搭建的。想着人活着并非永恒,总得留下点什么东西,而我对于这“留下的东西”的理解,就是对“永恒”的理解。
我最喜欢的耗子叔的一篇文章,就是《别让自己”墙“了自己》。因为真实,所以喜欢;因为喜欢,所以历历在目。不言而喻。
Autoscaler 中 VPA 的实现原理解析
Pod 自动垂直伸缩(Vertical Pod Autoscaler,VPA)是 K8s 中集群资源控制的重要一部分。它主要有两个目的:
- 通过自动化配置所需资源的方式来降低集群的维护成本
- 提升集群资源的利用率,减少集群中容器发生 OOM 或 CPU 饥饿的风险
本文以 VPA 为切入点,分析了 Autoscaler 和 Kubernetes In-Place 的 VPA 实现方式。
Autoscaler
此部分内容对应的代码基于 Autoscaler HEAD fbe25e1。
Autoscaler 的 VPA 会根据 Pod 的真实用量来自动的调整 Pod 所需的资源值,它通过引入 VerticalPodAutoscaler API 资源来实现,该资源定义了匹配哪些 Pod(label selector)使用何种更新策略(update policy)去更新以何种方式(resources policy)计算的资源值。
Autoscaler 的 VPA 由以下模块配合实现:
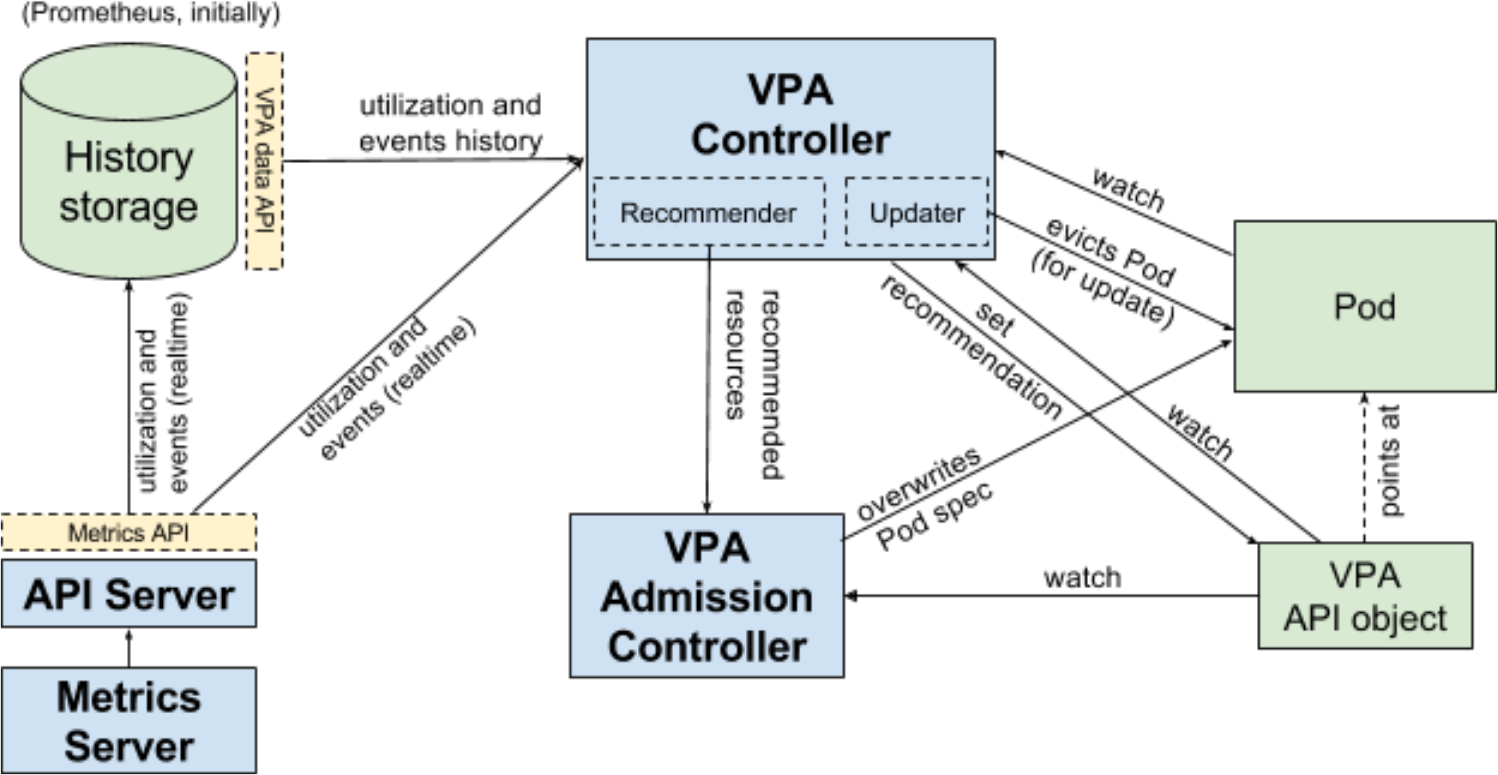
- Recommender,负责计算一个 VPA 对象中所匹配 Pod 的资源推荐值
- Admission Controller,负责拦截所有 Pod 的创建请求,并覆盖匹配到 VPA 对象的 Pod 资源值字段
- Updater,负责 Pod 资源的实时更新
GreptimeDB 的 KubeBlocks 集成经验分享
本文同为:
- Greptime 官方微信公众号推文:GreptimeDB 的 KubeBlocks 集成经验分享
- Greptime Official Blogs: Hands-on Experience of Integrating GreptimeDB with KubeBlocks

KubeBlocks 是什么
KubeBlocks 是一款由 ApeCloud 开源的云原生数据基础设施,旨在帮助应用开发者和平台工程师在 Kubernetes 上更好地管理数据库和各种分析型工作负载。KubeBlocks 支持多个云服务商,并且提供了一套声明式、统一的方式来提升 DevOps 效率。
KubeBlocks 目前支持关系型数据库、NoSQL 数据库、向量数据库、时序数据库、图数据库以及流计算系统等多种数据基础设施。
Cilium CNI: tc ReloadDatapath 工作原理解析
本文代码基于 Cilium HEAD 4093531 展开。
在 Cilium CNI 中,每当 CiliumEndpoint 被创建时,都会触发Loader.CompileAndLoad方法的执行。在之前的文章中提到过,Cilium 使用tc(traffic control)来将编译好的 BPF 程序加载到内核,但针对具体加载过程、加载内容并没有展开描述,因此本文借机来一探究竟。
// pkg/datapath/loader/loader.go
func (l *Loader) CompileAndLoad(ctx context.Context, ep datapath.Endpoint, stats *metrics.SpanStat) error {
if ep == nil {
log.Fatalf("LoadBPF() doesn't support non-endpoint load")
}
dirs := directoryInfo{
Library: option.Config.BpfDir, // /var/lib/cilium/bpf,存放 BPF 模版文件
Runtime: option.Config.StateDir, // /var/run/cilium,存放 endpoint 运行状态
State: ep.StateDir(), // /var/run/cilium/state/{endpoint-id}
Output: ep.StateDir(),
}
return l.compileAndLoad(ctx, ep, &dirs, stats)
}
func (l *Loader) compileAndLoad(ctx context.Context, ep datapath.Endpoint, dirs *directoryInfo) error {
err := compileDatapath(ctx, dirs, ep.IsHost(), ep.Logger(Subsystem)) // 编译 BPF 程序
err = l.reloadDatapath(ctx, ep, dirs) // 加载 BPF 程序
return err
}
Cilium CNI 工作原理解析
本文代码基于 Cilium HEAD 4093531,主要围绕 Cilium CNI 的 Operation 展开。
添加网络
Cilium CNI 对于 ADD Operation 的操作定义在plugins/cilium-cni/main.go中,并由cmdAdd函数描述,该函数主要负责为 Pod 创建网络,其整体的控制时序流如下图所示。下图中在 IP 地址分配环节,描述了三种 IPAM 方式(host-scope、crd 和 eni),本文只关注 host-scope 这种默认的分配方式,即标记了红色背景的流程部分。
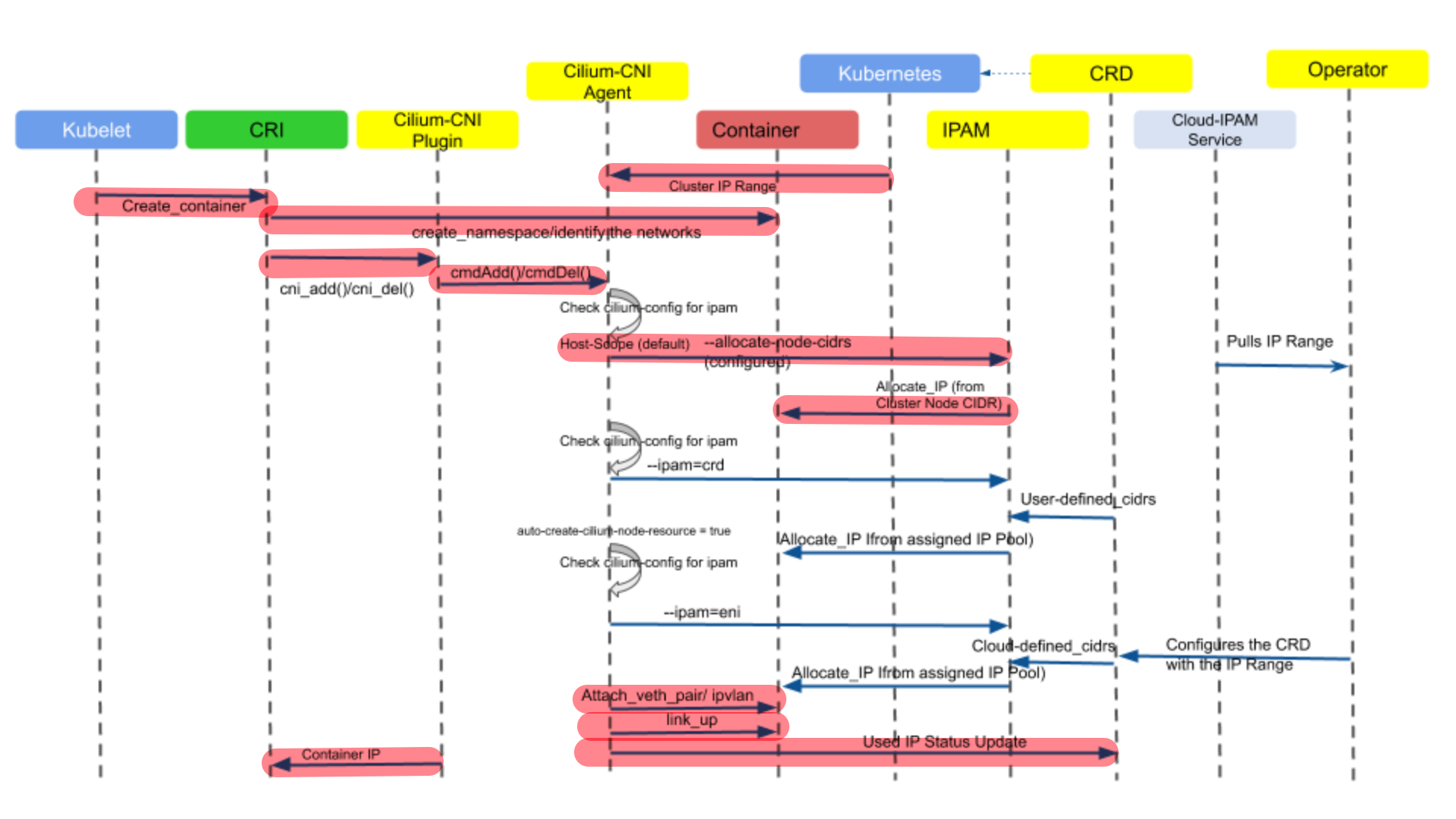
由于cmdAdd函数内容较多,下文将分段对其中重要的部分进行分析。
The Garbage Collection of Pods
本文代码基于 Kubernetes v1.27 展开。
在 K8s 中,对于执行或调度失败的 Pods 来说,它的 API 对象还依然会存在于集群中。及时的清理掉这些对象以防止资源泄露,就变得尤其重要。K8s 中存在一个名为 Pod GC 的 controller 专门负责回收这种对象,在已终止 Pods 的数量达到 kube-controller-manager 设置的terminated-pod-gc-threshold阈值之后,Pod GC 便会开始清理工作,见gcTerminated。
另外,Pod GC 也会清理符合以下条件的任何 Pods:
- 是孤儿 Pods,即绑定到了一个已经不存在的 Node 上,见
gcOrphaned - 是未经调度过就终止的 Pods,见
gcUnscheduledTerminating - 是正在终止的 Pods,并绑定到了一个未 Ready 且带有
node.kubernetes.io/out-of-service污点的 Node 上,见gcTerminating(启用NodeOutOfServiceVolumeDetach特性后)
// pkg/controller/podgc/gc_controller.go
// Pod GC controller 最终使用的方法
func (gcc *PodGCController) gc(ctx context.Context) {
// 列举出当前集群中所有 pod 和 node 的资源
pods, err := gcc.podLister.List(labels.Everything())
nodes, err := gcc.nodeLister.List(labels.Everything())
if gcc.terminatedPodThreshold > 0 { // 该阈值小于等于0,说明不启用 Pod GC,只进行一些其他的回收工作
gcc.gcTerminated(ctx, pods)
}
if utilfeature.DefaultFeatureGate.Enabled(features.NodeOutOfServiceVolumeDetach) {
gcc.gcTerminating(ctx, pods)
}
gcc.gcOrphaned(ctx, pods, nodes)
gcc.gcUnscheduledTerminating(ctx, pods)
}
13 post articles, 2 pages.